Redis安装与配置
Redis的安装
通过redis官网下载上传至服务器,或通过wget直接下载
Redis官网:https://redis.io/
AnotherRedisDesktopManager:Gitee下载地址
# 下载解压
wget http://download.redis.io/releases/redis-6.2.6.tar.gz
tar -zxvf redis-6.2.6.tar.gz
# 安装 (Ubuntu下最好在国外源下安装 gcc ,否则可能出错)
sudo apt-get install gcc # 需要先安装编译环境 ( centos: yum install gcc-c++ )
sudo chmod -R 777 redis-6.2.6/ # ubuntu可能存在权限问题,先赋予权限再安装
cd redis-6.2.6/ # 进入redis目录进行安装
make && make install不报错的话就已经在 /usr/local/bin/ 目录下生成了 redis-server 执行文件
如果是普通 (非root用户) 应该会报下面错误:

这时需要手动复制一些文件到指定目录
这里暂且为了多熟悉下Redis和linux,就不使用其默认的位置了,而是将执行文件和配置文件全放在了自定义的文件夹下
sudo mkdir -p /usr/local/redis/bin/ # sudo mkdir -p /usr/local/redis/bin/
sudo mkdir -p /usr/local/redis/conf/ # 存放配置文件目录
# 然后将Redis src下的编译好的可执行文件拷贝到 /usr/local/redis/bin/
# 配置文件拷贝到 /usr/local/redis/conf/
cd /usr/local/redis/redis-6.2.6/src
sudo cp redis-server redis-cli /usr/local/redis/bin/
sudo cp ../redis.conf /usr/local/redis/conf/
# 此时已经可以启动Redis了
cd /usr/local/redis
./bin/redis-server ./conf/redis.conf &
# ctrl+c正常会中断程序,加上&之后ctrl+c程序也不会退出
^C启动客户端连接试试:

# 这里先关闭 redis-server, 因为下面需要修改其配置文件
ps -ef|grep redis
kill -9 pid
# 修改配置文件之前别忘了先备份
sudo cp /usr/local/redis/conf/redis.conf /usr/local/redis/conf/redis.conf.backup
# 修改redis.conf
sudo vim /usr/local/redis/conf/redis.confRedis服务启动
redis安装包的 utils 目录下有一些便捷的服务脚本,如:redis_init_script , systemd-redis_server.service
分别为 /etc/init.d/xxx 脚本 , 和 systemctl 的脚本,
systemd的方式 (未配置成功,待解决……):
注:( 个人查看Ubuntu下的目录是
/lib/systemd/system, 但很多资料说的是 /usr/lib/systemd/system )对于那些支持 Systemd 的软件,安装的时候,会自动在
/usr/lib/systemd/system目录添加一个配置文件。如果你想让该软件开机启动,就执行下面的命令(以
httpd.service为例)。bash$ sudo systemctl enable httpd上面的命令相当于在
/etc/systemd/system目录添加一个符号链接,指向/usr/lib/systemd/system里面的httpd.service文件。这是因为开机时,
Systemd只执行/etc/systemd/system目录里面的配置文件。这也意味着,如果把修改后的配置文件放在该目录,就可以达到覆盖原始配置的效果
systemd有系统和用户区分:
系统(/user/lib/systemd/system/)、用户(/etc/lib/systemd/user/)
一般系统管理员手工创建的单元文件建议存放在/etc/systemd/system/目录下面。
/usr/lib/systemd/system目录自动存放启动文件的配置位置,里面一般包含有XXXXX.service
下面使用 systemd 的方式创建 Redis 的开机自启服务:
# 先将安装包下的 systemd 服务文件复制到 上述所说的位置
sudo cd /usr/local/redis/redis-6.2.6/utils/
sudo cp systemd-redis_server.service /usr/lib/systemd/user/redis-server.service
#修改配置文件位置
sudo vim /usr/lib/systemd/user/reids-server.service
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf --supervised systemd --daemonize yes
# 开机自启动
sudo systemctl enable redis-server.service
sudo systemctl start redis-server.service # 启动init方式:
# 复制 init 脚本到 /etc/init.d/ 下
cd /usr/local/redis/redis-6.2.6/utils/
sudo cp ./redis_init_script /etc/init.d/redis-server.service
# 修改脚本内容
sudo vim /etc/init.d/redis-server.service
EXEC=/usr/local/redis/bin/redis-server
CLIEXEC=/usr/local/redis/bin/redis-cli
CONF="/usr/local/redis/conf/redis.conf"
update-rc.d redis-server.service defaults 90 #开启自启动
/etc/init.d/redis-server.service start # 启动
ps -ef|grep redis
sudo kill -9 pid # 关闭这里采用快捷的安装方式,更详细的安装方式参照:redis的安装
docker pull redis:7.4.1
sudo mkdir -p /docker/redis/conf /docker/redis/data && \
sudo touch /docker/redis/conf/redis.conf
docker run -p 6379:6379 --name my-redis7 --restart=always \
-v /docker/redis/conf/redis.conf:/etc/redis/redis.conf \
-v /docker/redis/data:/data \
-d redis:7.4.1 redis-server /etc/redis/redis.conf进入容器内部:
docker exec -it my-redis7 /bin/bash
exitRedis常用配置
redis.conf :
daemonize yes # 让redis启动后在后台运行
dir /usr/local/redis/db # 修改redis的工作目录 (持久化文件的路径) sudo mkdir db
bind 0.0.0.0 # 0.0.0.0 表示所有的IP地址都可以连接并访问Redis服务器
requirepass itdrizzle # 设置密码
# 当客户端闲置多长时间后关闭连接,0表示不关闭连接
timeout 300
# 端口,一般不建议更改
port 6379
# 日志级别 DEBUG | VERBOSE | NOTICE | WARNING
loglevel DEBUG
# Redis默认有16个数据库
database 16redis-cli
启动redis客户端: redis-cli
redis-cli # 启动
redis-cli -a password shutdown # 关闭
redis-cli -a password ping # 查看是否存活 PONG表示正常redis-cli的基本使用:
> auth password # 类似登录(必须输入密码)
> set name tom # OK 设置name的值为tom
> get name # "tom" 获取name的值
> del name # (integer)1 返回删除的数量
> get name # (nil) 删除后再获取为空
> type age # string 返回age的类型
> keys * # 查看所有的key(不建议再生产上使用,有性能影响)
> mset # 连续设值 如:MSET key1 "Hello" key2 "World"
> mget # 连续取值
> msetnx # 连续设置,如果存在则不设置 Redis命令中心
Redis命令十分丰富,包括的命令组有Cluster、Connection、Geo、Hashes、HyperLogLog、Keys、Lists、Pub/Sub、Scripting、Server、Sets、Sorted Sets、Strings、Transactions一共14个redis命令组两百多个redis命令
Redis 命令中心:http://redis.cn/commands.html
Redis Commands:https://redis.io/commands/
| 命令组 | 描述 | 文档地址 |
|---|---|---|
| Connection | connection(连接) 相关的命令 | connection |
| Keys | 操作 key 的通用命令 | generic |
| Strings | string 类型相关的命令 | string |
| Lists | list 类型相关的命令 | list |
| Hashes | hash 类型相关的命令 | hash |
| Sets | set 类型相关的命令 | set |
| Sorted Sets | sorted set 类型相关的命令 | sorted set) |
| HyperLogLog | 基数统计 相关的命令 | hyperloglog |
| Geo | 地理位置信息 相关的命令 | geo |
| Steams | stream 相关的命令 | streams |
| Transactions | redis 事务的相关命令 | transactions |
| Scripting | redis 脚本常用命令 | scripting |
| Pub/Sub | 发布订阅 (pub/sub) 相关的命令 | pubsub |
| Server | 用于管理 redis 服务 | server |
| Cluster | Redis Cluster集群相关的命令 | cluster |
Redis持久化
Redis持久化存储有两种持久化方案:RDB(Redis DataBase)和AOF(Append-Only File)。
RDB是将内存中数据的快照(指定的时间间隔存储数据集的时间点快照)存储到磁盘内,
AOF则是通过日志记录Redis内的所有操作。redis服务重启时通过这些操作重建原始数据集
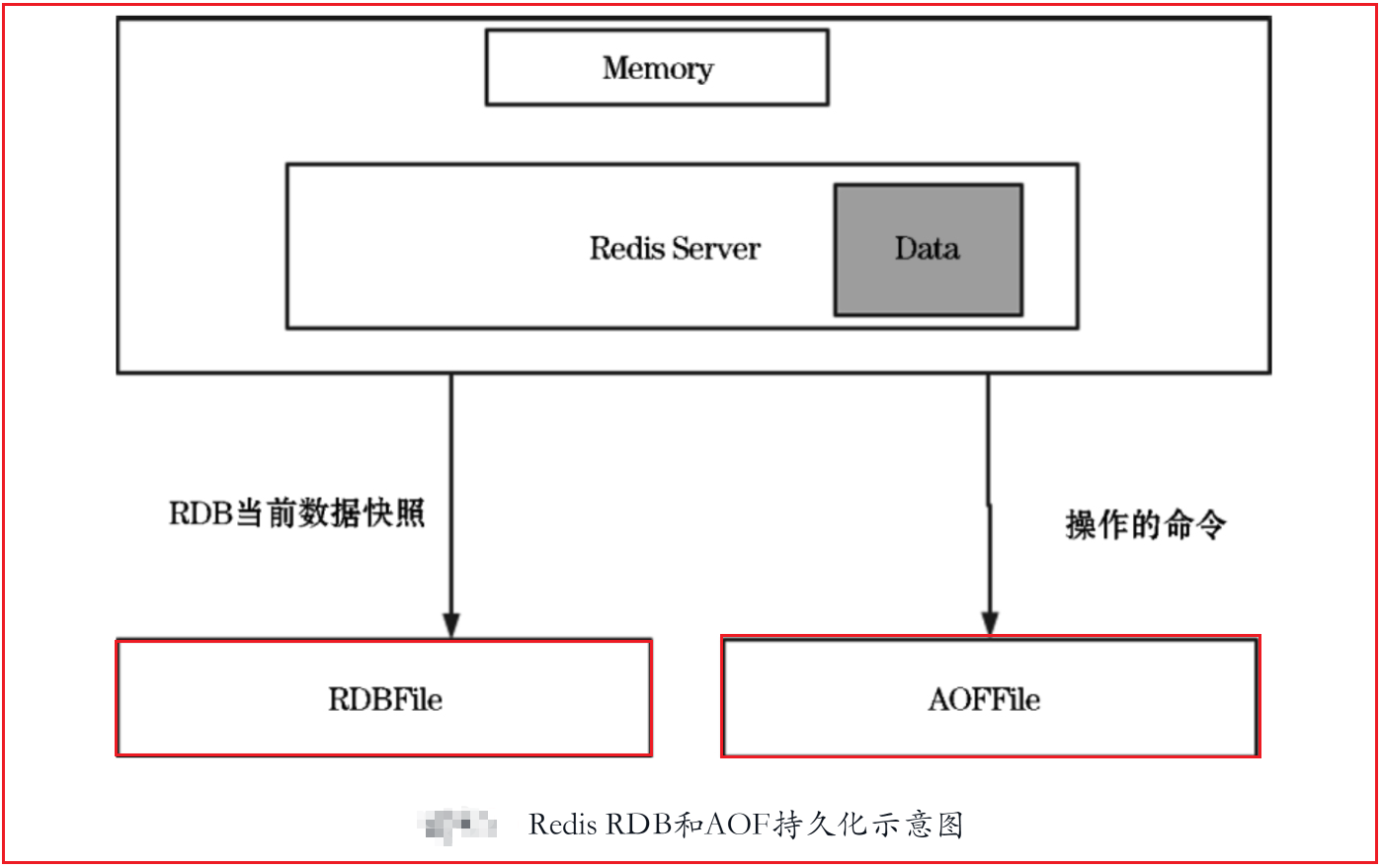
Redis 4之后支持AOF+RDB混合持久化的方式,结合了两者的优点,
可以通过aof-use-rdb-preamble配置项开启混合持久化功能的开关。
RDB(Redis DataBase)是将Redis内存中数据的快照写⼊到⼆进制⽂件中,是Redis的默认持久化方案。
触发RDB持久化的方式分别为:正常关闭redis、根据配置文件设置的次数定时触发、save和bgsave命令
-
以一段时间内达到指定修改的次数为规则来触发快照操作(在redis.conf中配置,快照文件名为dump.rdb)
每当Redis服务重启的时候都会从该文件中把数据加载到内存中。
-
使用save和bgsave命令手动来触发
save会阻塞服务器进程。在执行save命令的过程中,服务器不能处理任何请求
bgsave(background save,后台保存)命令会通过一个子进程在后台处理数据RDB持久化
本质上save和bgsave调用的都是rdbSave函数,所以Redis不允许save和bgsave命令同时执行,
当然这也是为了避免RDB文件数据出现不一致性的问题。
RDB持久化的配置文件:
# 默认定时持久化规则
save 900 1
save 300 10
save 60 10000
# 关闭:
# 1)注释掉所有save point 配置可以关闭 RDB 持久化。
# 2)在所有 save point 配置后增加:save "",该配置可以删除所有之前配置的 save point。
# 默认值为yes,当启用了RDB且最后一次在后台保存数据失败,Redis是否停止接收数据:
# yes代表可以继续写入数据;no代表不会写入成功,通知用户持久化出现错误
stop-writes-on-bgsave-error yes
# 持久化的数据是否进行压缩
rdbcompression yes
# 存储的快照是否进行CRC64算法的数据校验,如果希望获取到最大的性能提升,可以关闭此功能
Rdbchecksum yes
# 设置快照的文件名,默认是dump.rdb
dbfilename dump.rdb
dir /usr/local/redis/db # dump.rdb的存储位置RDB默认持久化策略默认有三种方式:
第一种:在60秒内有10000次操作即触发RDB持久化。
第二种:没有满足第一种条件时,在300秒内有10次操作即触发RDB持久化。
第三种:没有满足第二种条件时,在900秒内有1次操作即触发RDB持久化。
Redis有一个周期性操作函数,默认每隔100ms执行一次,其中的一项工作就是检查自动触发bgsave命令的条件是否成立
RDB全量备份总是非常耗时的,而且不能提供强一致性(Strict Consistency),即
-
如果Redis进程崩溃,那么在最近一次RDB备份之后的数据也会随之消失。
(⼩内存机器不适合使⽤,RDB机制符合要求才会照快照,可能会丢失数据)
-
在默认情况下,RDB数据持久化实时性比较差,而配置为高时效性时,频繁操作的成本则会很高
适⽤于容灾备份 、全量复制
AOF(Append Only File)以独立日志的方式记录每次的写命令,可以很好地解决了数据持久化的实时性。
系统重启时可以重新执行AOF文件中的命令来恢复数据。AOF会先把命令追加在AOF缓冲区,然后根据对应策略写入硬盘。
AOF持久化的相关配置:
# 开启AOF持久化
appendonly yes
# AOF文件名
appendfilename "appendonly.aof"
# AOF文件存储路径 (与rdb的一致)
dir dir /usr/local/redis/db
# aof文件比上次重写时增长100%(配置可以大于100%)时触发重写
auto-aof-rewrite-percentage 100
# aof文件大小超过64MB时触发重写
auto-aof-rewrite-min-size 64mb
// aof 持久化策略,任选一个,默认是everysec
# appendfsync always
appendfsync everysec
# appendfsync no
使用AOF持久化可以根据不同的fsync策略来备份数据,因为AOF采用的是追加的日志方式,
因此即使断电也不会出现磁盘寻道或磁盘被损坏的问题。
如果由于某种原因(磁盘已满或其他原因)日志只记录了一半,那么可以使用redis-check-aof工具轻松修复。
当数据量太大时,Redis能够在后台自动重写AOF,并生成一个全新的文件,其中包含创建当前数据集所需的最少操作集,
一旦准备好新的文件,Redis就会切换新的文件并开始把日志追加到新的文件。
AOF文件包含了所有操作的日志,而且很容易看懂,当用户不小心使用了flushall命令,flushall会把所有的数据删除,
但是可以根据AOF文件找到错误的命令,把这些错误的指令删除,然后重新启动Redis,就可以恢复对应的业务数据。
但是在此期间,AOF文件不能被重写,重写之后的AOF文件不再是可以让用户理解的内容。
AOF文件会以文本格式保存所有写操作命令,且未经压缩,因此对于同一数据集,AOF文件通常大于等效的RDB文件。RDB和AOF持久化的区别:使用RDB持久化会有数据丢失的风险,但是数据恢复的速度快;使用AOF持久化可以保证数据的完整性,但数据恢复的速度慢。
| 特性 \ 方式 | RDB(Redis DataBase) | AOF(Append Only File) | |
– | | 启动优先级 | 低 | 高 | | 文件体积 | 小 | 大 | | 恢复性能 | 速度快 | 速度慢 | | 数据安全性 | 丢失上次保存点之后的数据 | 因配置策略而不同 |
在Redis 4之后的版本新增了AOF+RDB混合模式,先使用RDB存储快照,然后使用AOF持久化记录所有的写操作,当满足重写策略或手动触发重写的时候,将最新的数据存储为新的RDB记录。重启服务时会从RDB和AOF两部分恢复数据,既保证了数据的完整性,又提高了数据恢复的性能。
开启AOF+RDB混合模式持久化的配置命令如下:
# redis.conf
aof-use-rdb-preamble yes只要在redis.conf配置文件中写入上面这行代码就可以开启AOF+RDB混合模式。(注意此模式在Redis 4及以上版本才支持)。在 redis 4 刚引入时,默认是关闭混合持久化的,但是在 redis 5 中默认已经打开了。
混合持久化并不是一种全新的持久化方式,而是对已有方式的优化。混合持久化只发生于 AOF 重写过程。使用了混合持久化,重写后的新 AOF 文件前半段是 RDB 格式的全量数据,后半段是 AOF 格式的增量数据。
-
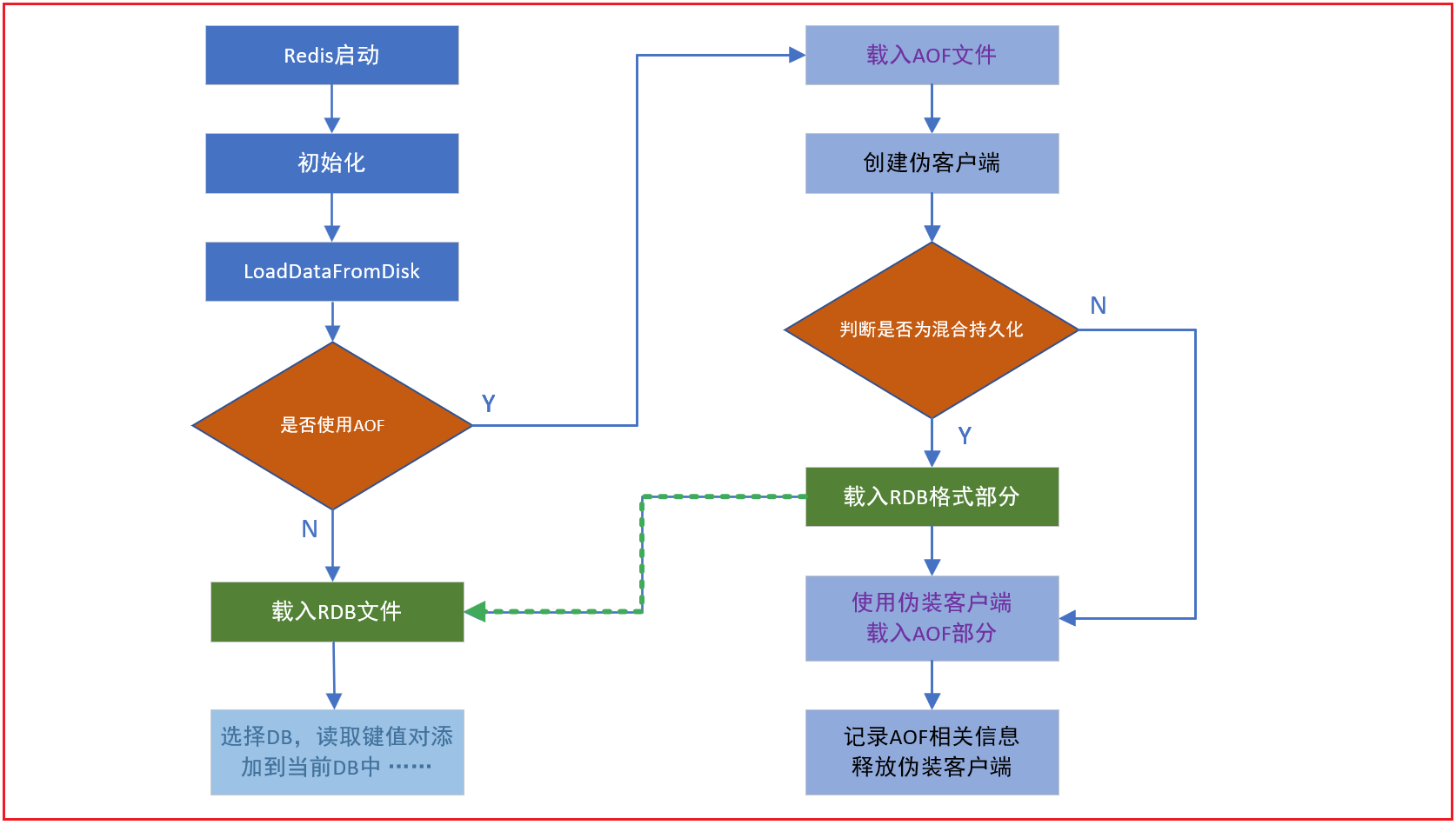
开启混合模式后,在bgrewriteaof命令之后会在AOF文件中以RDB格式写入当前最新的数据,之后的写操作继续以AOF的追加形式追加写命令。当Redis重启的时候,先加载RDB的部分再加载剩余的AOF部分。
-
混合持久化本质是通过 AOF 后台重写(bgrewriteaof 命令)完成的,不同的是当开启混合持久化时,fork 出的子进程先将当前全量数据以 RDB 方式写入新的 AOF 文件,然后再将 AOF 重写缓冲区(aof_rewrite_buf_blocks)的增量命令以 AOF 方式写入到文件,写入完成后通知主进程将新的含有 RDB 格式和 AOF 格式的 AOF 文件替换旧的的 AOF 文件。
优点:结合 RDB 和 AOF 的优点, 更快的重写和恢复。
缺点:AOF 文件里面的 RDB 部分不再是 AOF 格式,可读性差。
一般来说, 如果想尽量保证数据安全性, 你应该同时使用 RDB 和 AOF 持久化功能,同时可以开启混合持久化。如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。如果你的数据是可以丢失的,则可以关闭持久化功能,在这种情况下,Redis 的性能是最高的
使用 Redis 通常都是为了提升性能,而如果为了不丢失数据而将 appendfsync 设置为 always 级别时,对 Redis 的性能影响是很大的,在这种不能接受数据丢失的场景,其实可以考虑直接选择 MySQL 等类似的数据库。
简单来说,如果同时启用了 AOF 和 RDB,Redis 重新启动时,会使用 AOF 文件来重建数据集,因为通常来说,AOF 的数据会更完整。
而在引入了混合持久化之后,使用 AOF 重建数据集时,会通过文件开头是否为“REDIS”来判断是否为混合持久化
具体流程如下图所示:
Redis的数据类型
Redis⽀持五种数据类型:String(字符串),hash(哈希),list(列表),set(集合)以及 zset(sorted set:有序集合) 等
REDIS data-types-intro:http://redis.cn/topics/data-types-intro.html
Redis数据类型相关的通用命令:
# 通常用SET command 和 GET command来设置和获取字符串值
> set mykey somevalue
> get mykey
# SET 命令有些有趣的操作,例如,当key存在时SET会失败,或相反的,当key不存在时它只会成功
> set mykey newval nx #(nil)
> set mykey newval xx # OK
# 使用MSET和MGET命令, 一次存储或获取多个key对应的值 (MGET 命令返回由值组成的数组)
> mset a 10 b 20 c 30
> mget a b c
# 使用EXISTS命令返回1或0标识给定key的值是否存在,使用DEL命令可以删除key对应的值
> set mykey hello
> exists mykey # (integer)1
> del mykey # (integer)1
> exists mykey # (integer)0
# TYPE命令可以返回key对应的值的存储类型:
> set mykey x # OK
> type mykey # string
> del mykey # (integer) 1
> type mykey # none
# Redis超时:数据在限定时间内存活 (可以对key设置一个超时时间,当这个时间到达后会被删除)
> set key some-value # OK
> expire key 5 # (integer) 1 设置过期时间(默认单位为seconds)
> get key (immediately) # "some-value"
> get key (after some time) # (nil)
# 也可以再次调用这个命令来改变超时时间,使用PERSIST命令去除超时时间 (TTL命令用来查看key对应的值剩余存活时间)
> set key 100 ex 10 # OK 设置带过期时间的数据 或 改变超时时间 (默认单位为seconds)
> ttl key # (integer) 9 查看剩余时间, -1永不过期, -2过期Redis Strings
二进制安全的字符串、Commands:https://redis.io/commands/?group=string
> set rekey data # 设置已经存在的key ,会覆盖
> setnx rekey data # 设置已经存在的key ,不会覆盖
> append key value # 合并字符串,将value合并到key对应的值上
> strlen key # 字符串长度
> incr key # 累加1 (类似 a+=1 的效果)
> decr key # 累减1
> incrby key num # 累加给定数值
> decrby key num # 累减给定数值
> getrange key start end # 截取数据, end=-1代表到最后
> setrange key start newdata # 从start位置开始替换数据应用场景:
-
缓存 token (或类似的单个值的缓存)
-
作为计数器:如统计网站的访问量(日访问量 = 日pv,page view),通过incr这个指令来做
还有用户的总点赞数、关注数、粉丝数、帖子的评论数、热度、文章的阅读数和收藏数等
-
其他所有的数据结构最后都可以使用String来实现
Redis Hashes
REDIS data-types-intro:http://redis.cn/topics/data-types-intro.html#hashes
Redis hash :由field和关联的value组成的map。field和value都是字符串的。
Redis hash 看起来就像一个 “hash” 的样子,由键值对组成,类似map ,存储结构化数据结构,比如存储一个对象 (不能有嵌套对象)
Hash 便于表示 objects,实际上,你可以放入一个 hash 的域数量实际上没有限制(除了可用内存以外)
# `HMSET` 指令设置 hash 中的多个域:
> hmset user:1001 username zhangsan birthday 1999 verified 1
OK
> type user:1001 # hash
> hget user:1001 username # "zhangsan" `HGET` 取回单个域。
> hmget user:1001 username other # `HMGET` 和 `HGET` 类似,但返回一系列值:
1) "zhangsan"
2) (nil)
> hgetall user:1001
1) "username"
2) "zhangsan"
3) "birthday"
4) "1999"
5) "verified"
6) "1"
> hincrby user age 2 #累加属性
> hincrbyfloat user age2.2 #累加属性
> hlen user #有多少个属性
> hexists user age #判断属性是否存在
> hkeys user #获得所有属性
> hvals user #获得所有值
> hdel user field1 field2 #删除指定的对象属性应用场景:
-
hash这种数据结构,可以天然的帮助我们存储对象
例如登录之后,存储用户这个对象的信息,电商应用中,缓存购物车信息
Redis lists
REDIS data-types-intro:http://redis.cn/topics/data-types-intro.html#lists
list 按插入顺序排序的字符串元素的集合。 Redis lists基于Linked Lists实现。
这意味着即使在一个list中有数百万个元素,在头部或尾部添加一个元素的操作,其时间复杂度也是常数级别的。
用LPUSH 命令在十个元素的list头部添加新元素,和在千万元素list头部添加新元素的速度相同。
那么,坏消息是什么?在数组实现的list中利用索引访问元素的速度极快,而同样的操作在linked list实现的list上没有那么快。
Redis Lists用linked list实现的原因是:对于数据库系统来说,至关重要的特性是:能非常快的在很大的列表上添加元素。
另一个重要因素是,正如你将要看到的:Redis lists能在常数时间取得常数长度。
如果快速访问集合元素很重要,建议使用可排序集合(sorted sets)。可排序集合我们会随后介绍。lpush list1 pig cow sheep chicken duck
lpush userList 1 2 3 4 5 #构建一个list ,从左边开始存入数据(最后存入的数据在最左面)
rpush userList 1 2 3 4 5 #构建一个list ,从右边开始存入数据(最后存入的数据在最右面)
llen list #list长度
lindex list index #获取list指定下标的值
lset list index value #把某个下标的值替换
lrange list start end #获得数据 (-1表示最后一个元素,-2表示list中的倒数第二个元素,以此类推)
lpop #从左侧开始拿出(并删除)一个数据
rpop #从右侧开始拿出(并删除)一个数据
lrem list num value #删除num个相同的value
ltrim list start end #把list从左边截取指定长度,并赋值给原来的list
linsert list before/after value newValue #在value的前/后插入一个新的值应用场景:
- 可以用作消息队列
- 可以用作消息未读清单(例如:bilibili)
key 的自动创建和删除 :
目前为止,在我们的例子中,我们没有在推入元素之前创建空的 list,或者在 list 没有元素时删除它。在 list 为空时删除 key,并在用户试图添加元素(比如通过 LPUSH)而键不存在时创建空 list,是 Redis 的职责。
这不光适用于 lists,还适用于所有包括多个元素的 Redis 数据类型 – Sets, Sorted Sets 和 Hashes。
基本上,我们可以用三条规则来概括它的行为:
- 当我们向一个聚合数据类型中添加元素时,如果目标键不存在,就在添加元素前创建空的聚合数据类型。
- 当我们从聚合数据类型中移除元素时,如果值仍然是空的,键自动被销毁。
- 对一个空的 key 调用一个只读的命令,比如
LLEN(返回 list 的长度),或者一个删除元素的命令,将总是产生同样的结果。该结果和对一个空的聚合类型做同个操作的结果是一样的。
规则 1 示例:
> del mylist # (integer) 1
> lpush mylist 1 2 3 # (integer) 3但是,我们不能对存在但类型错误的 key 做操作:
> set foo bar
OK
> lpush foo 1 2 3
(error) WRONGTYPE Operation against a key holding the wrong kind of value
> type foo
string规则 2 示例:
> lpush mylist 1 2 3 # (integer) 3
> exists mylist # (integer) 1
> lpop mylist # "3"
> lpop mylist # "2"
> lpop mylist # "1"
> exists mylist # (integer) 0所有的元素被弹出之后, key 不复存在。
规则 3 示例:
> del mylist # (integer) 0
> llen mylist # (integer) 0
> lpop mylist # (nil)Redis Sets
REDIS data-types-intro:http://redis.cn/topics/data-types-intro.html#sets
set 集合, Redis Set 是 String 的无序排列 (不重复且无序的字符串元素的集合)
# SADD 指令把新的元素添加到 set 中
sadd set1 cow sheep pig duck sheep #新建集合并向其中添加不重复的元素
srandmember set1 2 #随机获取集合中的两个元素
smembers set1 #查看全部集合元素
scard set1 #统计个数
sismember set1 pig #判断pig是否为set1的元素 (一个特定的元素是否存在?)
srem set1 pig #删除set1中的pig
spop set1 2 #随机删除两个元素
smove set2 set1 10 #将set2中的10转移到set1中
# 求差集 (即剔除set1 中 set1和set2交集 的那部分)
# 也可以说返回set1中存在而set2中不存在的元素
sdiff set1 set2
sinter set1 set2 #求交集
sunion set1 set2 #求并集应用场景:
- 利用随机的特性,可以帮助我们 抽奖、点名、投票等等
- 利用set的并集特性,求共同的好友,进行好友推荐等业务
Redis Sorted sets
REDIS data-types-intro:http://redis.cn/topics/data-types-intro.html#sorted-sets
Sorted sets are a data type which is similar to a mix between a Set and a Hash.
Like sets, sorted sets are composed of unique, non-repeating string elements, so in some sense a sorted set is a set as well.
every element in a sorted set is associated with a floating point value, called the score (this is why the type is also similar to a hash, since every element is mapped to a value).
zadd zset 10 value1 20 value2 30 value3 #设置member和对应的分数
zrange zset 0 -1 #查看所有zset中的内容
zrange zset 0 -1 withscores #...带有分数
zrank zset value #获得对应的下标、The rank (or index) is 0-based
zscore zset value #获得对应的分数
zcard zset #统计个数
zcount zset 分数1 分数2 #统计个数[包含边界]
zrangebyscore zset分数1 分数2 #查询分数之间的member(包含分数1 分数2)
zrangebyscore zset (分数1 (分数2 #查询分数之间的member (不包含分数1和分数2 )
# 查询分数之间的member(包含分数1 分数2) ,获得的结果集再次根据下标区间做查询
zrangebyscore zset 分数1 分数2 limit start end
zrem zset value #删除member应用场景:
- 积分排行榜、新闻排行榜、直播打赏排名等