数组、切片、映射与结构体的选择
| 数据结构 | 何时使用 | 优点 | 缺点 |
|---|---|---|---|
| 数组 (Array) | 当你需要一个固定大小的集合,并且长度是类型的重要部分时。例如,表示一个RGB颜色值 [3]byte。 |
性能高,内存布局紧凑,无需额外头信息。 | 长度固定,不灵活,值传递开销大。 |
| 切片 (Slice) | 绝大多数情况下用于处理序列数据。它是Go中最常用的集合类型。 | 动态长度,灵活,引用传递效率高。 | 共享底层数组可能导致意外修改。 |
| 映射 (Map) | 当你需要通过一个唯一的键来快速查找、存储和删除值时。 | 键值查找非常快(O(1) 复杂度)。 | 无序,不是并发安全的。 |
| 结构体 (Struct) | 当你需要将不同类型的数据字段组合成一个逻辑实体时。例如,定义一个用户、一个订单等。 | 提升代码可读性和组织性,是定义自定义类型的基础。 | 字段固定,不适合存储动态数量的同类数据。 |
数组(Array)及其使用
数组是Go语言中一种基础的数据结构,它是一个具有固定长度且包含相同类型元素的集合。
核心特性:
- 固定长度:数组的长度在声明时就已确定,并且是其类型的一部分。例如,
[3]int和[4]int是两种不同的、不兼容的类型。 - 值类型 (Value Type):数组在Go中是值类型。当一个数组被赋值给另一个变量,或作为函数参数传递时,会创建该数组的完整副本。
声明与初始化
package main
import "fmt"
func main() {
// 1. 声明一个数组,元素会被初始化为零值
var arr1 [3]int // arr1 是 [0 0 0]
// 2. 声明并初始化
var arr2 [3]int = [3]int{1, 2, 3}
// 3. 使用类型推断和短声明
arr3 := [3]string{"a", "b", "c"}
// 4. 使用 ... 让编译器自动计算长度
arr4 := [...]int{10, 20, 30, 40} // 长度为4
// 5. 初始化指定索引的元素
arr5 := [5]int{1: 10, 3: 30} // arr5 是 [0 10 0 30 0]
fmt.Println("arr1:", arr1)
fmt.Println("arr2:", arr2)
fmt.Println("arr3:", arr3)
fmt.Printf("arr4: %v, len: %d\n", arr4, len(arr4))
fmt.Println("arr5:", arr5)
}
// 输出:
// arr1: [0 0 0]
// arr2: [1 2 3]
// arr3: [a b c]
// arr4: [10 20 30 40], len: 4
// arr5: [0 10 0 30 0]访问与修改
通过索引(从0开始)来访问和修改数组元素。
arr := [3]int{1, 2, 3}
arr[0] = 100 // 修改第一个元素
fmt.Println(arr[0]) // 输出: 100
fmt.Println(arr) // 输出: [100 2 3]遍历数组
通常使用 for 循环或 for range 循环来遍历。
arr := [...]string{"Apple", "Banana", "Cherry"}
// 使用传统 for 循环
for i := 0; i < len(arr); i++ {
fmt.Println(arr[i])
}
// 使用 for range (更推荐)
for index, value := range arr {
fmt.Printf("Index: %d, Value: %s\n", index, value)
}Common Pitfall: 数组是值类型 将数组作为函数参数传递时,函数内部操作的是数组的副本,不会影响原始数组。
gofunc modifyArray(arr [3]int) { arr[0] = 999 // 只会修改传入的副本 } func main() { original := [3]int{1, 2, 3} modifyArray(original) fmt.Println(original) // 输出: [1 2 3],原数组未变 }
Note: 要在函数中修改原数组,必须传递数组的指针 *[3]int。然而,在实际开发中,由于数组长度固定且传值成本高,我们极少直接使用数组作为函数参数,而是使用更灵活的切片(Slice)。
切片(Slice)及其应用
切片是 Go 语言中最重要、最常用的数据结构之一。它是一个动态长度的序列,底层是对一个数组的引用或视图。
- 引用类型 (Reference Type):切片本身不存储数据,它只是指向一个底层数组。多个切片可以共享同一个底层数组。
- 动态长度:切片的长度可以改变,通过
append函数增加元素。 - 结构: 一个切片包含三个部分:
- 指针 (Pointer): 指向底层数组的第一个元素。
- 长度 (Length,
len): 切片中实际包含的元素数量。 - 容量 (Capacity,
cap): 从切片的起始元素到底层数组末尾的元素数量。
实际应用中,可以将切片(Slice)视为Go语言的动态数组
创建与初始化
package main
import "fmt"
func main() {
// 1. 从数组创建切片
arr := [...]int{0, 1, 2, 3, 4, 5, 6}
s1 := arr[2:5] // 包含索引2, 3, 4的元素. s1: [2 3 4]
// 2. 使用切片字面量 (最常用)
s2 := []string{"Go", "Python", "Java"}
// 3. 使用 make 函数
// make([]T, len, cap)
s3 := make([]int, 5, 10) // len=5, cap=10, 元素为零值: [0 0 0 0 0]
s4 := make([]int, 5) // len=5, cap=5
// 4. 创建一个 nil 切片
var s5 []int // s5 是 nil, len=0, cap=0
fmt.Printf("s1: %v, len=%d, cap=%d\n", s1, len(s1), cap(s1))
fmt.Printf("s2: %v, len=%d, cap=%d\n", s2, len(s2), cap(s2))
fmt.Printf("s3: %v, len=%d, cap=%d\n", s3, len(s3), cap(s3))
fmt.Printf("s4: %v, len=%d, cap=%d\n", s4, len(s4), cap(s4))
fmt.Printf("s5: %v, len=%d, cap=%d, is nil? %t\n", s5, len(s5), cap(s5), s5 == nil)
}
// 输出:
// s1: [2 3 4], len=3, cap=5
// s2: [Go Python Java], len=3, cap=3
// s3: [0 0 0 0 0], len=5, cap=10
// s4: [0 0 0 0 0], len=5, cap=5
// s5: [], len=0, cap=0, is nil? true切片常用操作
-
截取操作(Slicing):
slice[low:high]操作不会创建新的数据,它只是创建一个新的切片“描述符”,其指针指向底层数组的low索引位置,并设置新的长度和容量。这个操作非常快速和高效。 多个切片可以指向同一个底层数组。修改其中一个切片中的元素会影响到其他共享该数组的切片。 -
追加 (Appending):
append(s, ...)扩容机制:- 容量充足时:
append直接在底层数组的空余位置上添加新元素,并返回一个更新了长度的切片。没有内存分配和数据拷贝。 - 容量不足时:
append会分配一个全新的、更大的底层数组,将旧数组的数据全部拷贝到新数组,然后添加新元素。这个过程涉及内存分配和数据复制,开销较大。
- 容量充足时:
-
复制 (Copying):
copy(dst, src)将src切片的元素复制到dst切片。
s := []int{10, 20, 30, 40, 50}
// 截取
sub1 := s[1:3] // [20, 30]
sub2 := s[:2] // [10, 20]
sub3 := s[3:] // [40, 50]
// 追加
s = append(s, 60, 70) // s 变为 [10 20 30 40 50 60 70]
// 复制
dst := make([]int, 3)
copy(dst, s) // dst 变为 [10 20 30]Common Pitfall:
append必须将结果赋回原变量append可能会(也可能不会)分配一个新的底层数组。如果超出现有容量,它会创建一个新的、更大的数组,并将所有元素复制过去。因此,append的返回值可能是一个指向新内存地址的新切片。必须总是将append的结果赋回原始切片变量。goslice := []int{1, 2} append(slice, 3) // 错误!append的返回值被丢弃了 fmt.Println(slice) // 结果可能还是 [1 2],也可能不是,行为未定义 // 正确做法 slice = append(slice, 3)
Common Pitfall: 切片共享底层数组 修改一个切片会影响到共享同一个底层数组的其他切片。
gobase := []int{1, 2, 3, 4, 5} s1 := base[0:3] // [1, 2, 3] s2 := base[2:5] // [3, 4, 5] s1[2] = 100 // 修改 s1 的一个元素 fmt.Println("base:", base) // 输出: base: [1 2 100 4 5] fmt.Println("s1:", s1) // 输出: s1: [1 2 100] fmt.Println("s2:", s2) // 输出: s2: [100 4 5] (s2 也受到了影响)Best Practice: 当你需要创建一个独立的切片副本,或者想防止意外修改时,使用
copy函数或创建一个容量恰好等于长度的新切片。
Common Pitfall: 切片中隐藏的数据(内存泄漏风险) 如果从一个非常大的切片中创建一个很小的切片,只要这个小切片存在,整个大数组就不会被垃圾回收,这可能导致内存泄漏。
gofunc getFirstThree() []byte { largeSlice := make([]byte, 10 * 1024 * 1024) // 10MB return largeSlice[:3] // 返回的小切片仍然引用着整个10MB的数组 } // 正确做法:只拷贝需要的数据 func getFirstThreeCorrect() []byte { largeSlice := make([]byte, 10 * 1024 * 1024) result := make([]byte, 3) copy(result, largeSlice) // copy只会复制len(result)个元素 return result // largeSlice 可以被GC回收 }
slice源码浅析
在 Go 源码 src/runtime/slice.go 文件中,定义了一个名为 slice 的结构体。一个 slice 变量,在内存中就是一个 slice 结构体的实例。
这就是它的定义:
// src/runtime/slice.go
type slice struct {
array unsafe.Pointer // 指向底层数组的指针
len int // 切片的当前长度
cap int // 切片的容量
}解析:
- 它就是一个结构体:
slice就是一个包含三个字段的、非常普通的结构体。在64位系统上,它占用24个字节(指针8字节 + len 8字节 + cap 8字节)。 - 赋值行为 (
s2 := s1): 当你执行这个操作时,Go 会进行结构体的浅拷贝。s2会得到一个与s1内容完全相同的、新的slice结构体副本。 - 共享数据的根源: 因为
s2是s1的副本,所以s2.array这个指针字段的值和s1.array的值是一样的。它们都指向了同一块底层数组内存。这就是为什么通过s2修改元素会影响到s1的根本原因。
映射(Map)-键值对
Map 是 Go 语言中无序的键值对(key-value)集合。它是一种哈希表的实现,提供了快速的键查找、添加和删除操作。
- 无序性: 遍历 map 时,元素的顺序是随机的,不能依赖于插入顺序。
- 引用类型: Map 也是引用类型。当一个 map 变量被赋值给另一个变量时,它们都指向同一个底层数据结构。
- 键的类型: Map 的键必须是可比较的类型,如
int,string,bool,pointer,struct(需要所有字段都可比较) 等。slice,map,function不能作为键。
创建及初始化
package main
import "fmt"
func main() {
// 1. 使用 make 函数创建 (最常用)
ages := make(map[string]int)
// 2. 使用 map 字面量
scores := map[string]int{
"Alice": 95,
"Bob": 88,
}
// 3. 创建一个 nil map
var nilMap map[string]int // nilMap 是 nil
fmt.Println("ages:", ages)
fmt.Println("scores:", scores)
fmt.Printf("nilMap: %v, is nil? %t\n", nilMap, nilMap == nil)
}
// 输出:
// ages: map[]
// scores: map[Alice:95 Bob:88]
// nilMap: map[], is nil? true操作Map
scores := make(map[string]int)
// 添加或更新
scores["Alice"] = 95
scores["Bob"] = 88
scores["Alice"] = 100 // 更新Alice的分数
// 获取
aliceScore := scores["Alice"]
fmt.Println("Alice's score:", aliceScore)
// 删除
delete(scores, "Bob")
fmt.Println("After deleting Bob:", scores)判断键是否存在:“comma, ok” 从 map 中获取一个不存在的键会返回该值类型的零值。为了区分键是真实存在且值为零,还是根本不存在,必须使用 “comma, ok” 语法。
scores := map[string]int{"Alice": 100, "Bob": 0}
// 安全地检查键是否存在
score, ok := scores["Charlie"]
if ok {
fmt.Printf("Charlie's score is %d\n", score)
} else {
fmt.Println("Charlie is not in the map.")
}
// 输出: Charlie is not in the map.遍历Map
使用 for range 遍历 map,每次迭代返回一个键和一个值。
for name, score := range scores {
fmt.Printf("%s has a score of %d\n", name, score)
}
// 输出 (顺序是随机的):
// Alice has a score of 100
// Bob has a score of 0Common Pitfall: 对
nilMap 进行写操作会引发 panic Map 在使用前必须使用make进行初始化。对nilmap 进行读操作是安全的(会返回零值),但写操作会立即导致程序崩溃。govar m map[string]int // m is nil // m["key"] = 1 // panic: assignment to entry in nil map // 正确做法 m = make(map[string]int) m["key"] = 1
Common Pitfall: 不能直接修改Map中结构体的值 Map 中的元素(包括结构体)是不可寻址的。因此,你不能直接修改 Map 中一个结构体值的字段。
gotype User struct{ Age int } m := map[string]User{"alice": {Age: 30}} // m["alice"].Age = 31 // 编译错误: cannot assign to struct field m["alice"].Age in map // 正确做法1:取出、修改、放回 tempUser := m["alice"] tempUser.Age = 31 m["alice"] = tempUser // 正确做法2:使用结构体指针作为Map的值 mPtr := map[string]*User{"alice": {Age: 30}} mPtr["alice"].Age = 31 // 正确,因为我们修改的是指针指向的内容
Common Pitfall: Map的并发访问不安全 Go 的 map 类型本身不是并发安全的。如果在没有锁保护的情况下,多个 goroutine 同时对同一个 map 进行读写操作,程序会崩溃(
fatal error: concurrent map read and map write)。Best Practice: 对于需要并发访问的 map,必须使用
sync.Mutex或sync.RWMutex进行保护,或者使用 Go 1.9 引入的sync.Map。
map源码浅析
map 在源码中的真实身份:hmap 结构体的指针。
- 一个
map类型的变量,在内存中就是一个指向hmap结构体的指针。 - 当声明
var m map[string]int时,m的类型在运行时可以理解为*hmap。
hmap 和它的核心组件 bmap(哈希桶)定义在 src/runtime/map.go 文件中。
hmap 结构体(哈希表头部)
这是 map 的“大脑”和“控制中心”。它包含了 map 的所有元数据。
// src/runtime/map.go
// A header for a Go map.
type hmap struct {
count int // map中元素的数量,len()函数就是返回它
flags uint8
B uint8 // 哈希桶数量的对数,即 buckets 数量 = 2^B
noverflow uint16 // 溢出桶的大约数量
hash0 uint32 // 哈希种子,用于计算哈希值
buckets unsafe.Pointer // 指向桶数组的指针,数组大小为 2^B
oldbuckets unsafe.Pointer // 扩容时指向旧桶数组的指针
nevacuate uintptr // 扩容进度计数器
// ... 其他字段
}
bmap 结构体(哈希桶)
hmap.buckets 指针指向的就是一个由 bmap 组成的数组。bmap 才是真正存储键值对的地方。
// src/runtime/map.go
// A bucket for a Go map.
type bmap struct {
// tophash 存储了每个key的哈希值的高8位,用于快速定位
tophash [8]uint8
// keys, values 和 overflow 字段在编译时会根据map的具体类型确定
// 其内存布局大致如下:
// keys [8]keytype
// values [8]valuetype
// overflow *bmap (指向下一个溢出桶的指针)
}解析:
- map是一个指针:
map变量本身就是一个指针。它的零值是nil。 - 赋值行为 (
m2 := m1): 当执行这个操作时,只是在复制这个指针。m1和m2现在是两个内容相同的指针,它们都指向了同一个hmap结构体实例。 - 共享数据的根源: 因为
m1和m2指向的是同一个hmap对象,所以任何通过m2进行的操作(如m2["key"] = value),都会直接修改这个共享的hmap及其关联的bmap。m1自然也能看到这些变化。
map的核心数据结构
go 的 map 真正存储数据(键值对)的是一个由 bmap(桶)结构体组成的数组
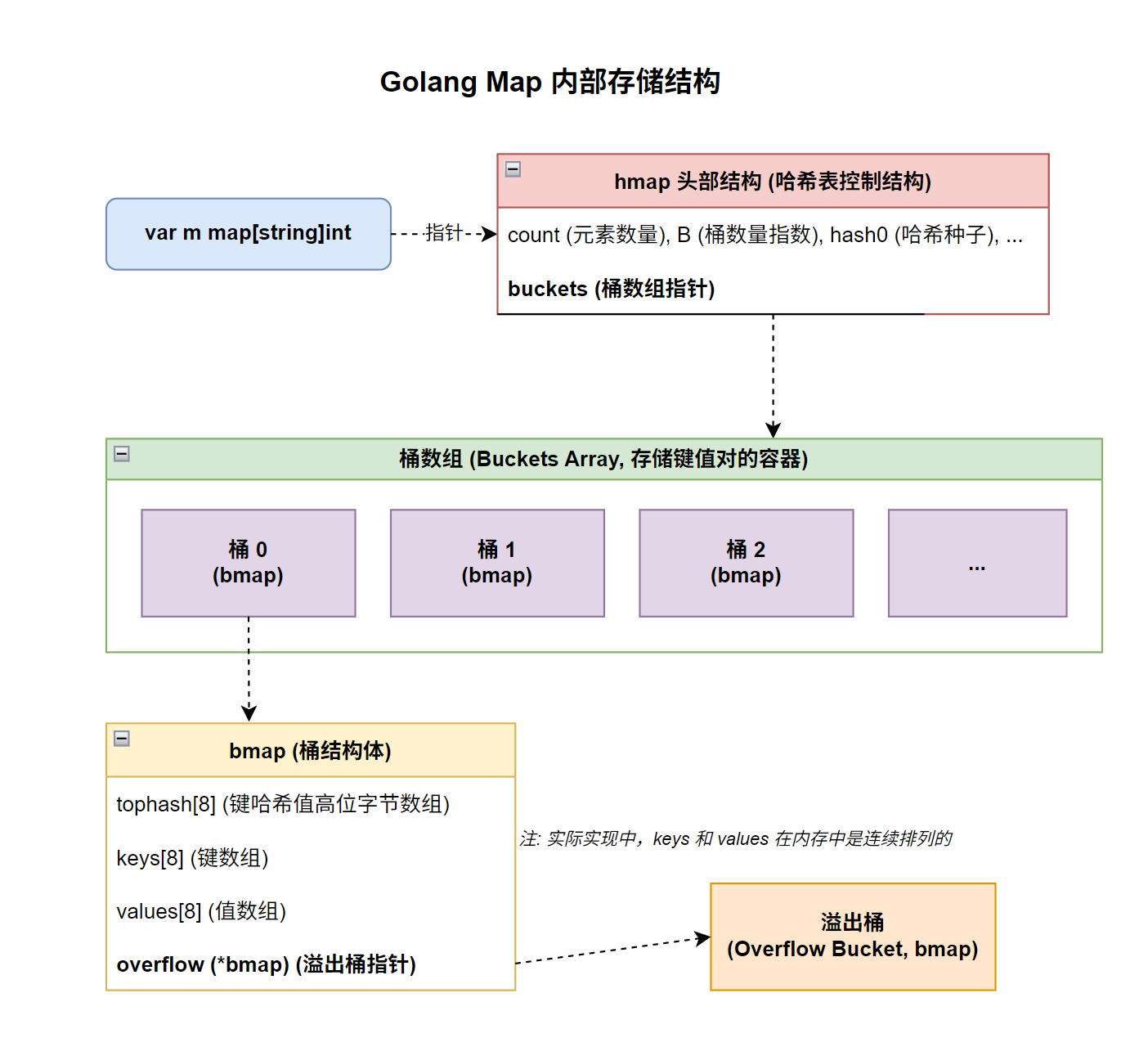
Go map 的核心是两个结构体:hmap 和 bmap。
1. hmap (The Map Header)
hmap 是 map 在运行时的头部表示,当你创建一个 map 时,你实际上得到的是一个指向 hmap 结构体的指针。它包含了 map 的所有元信息。
// A header for a Go map.
type hmap struct {
count int // map中元素的数量,len()函数就是返回它
flags uint8 // 状态标记 (e.g., 是否有写操作,是否在迭代)
B uint8 // 哈希桶数量的对数,即 buckets = 2^B
noverflow uint16 // 溢出桶的大约数量
hash0 uint32 // 哈希种子,用于计算哈希值,每次创建map都不同
buckets unsafe.Pointer // 指向桶数组的指针,数组大小为 2^B
oldbuckets unsafe.Pointer // 扩容时指向旧桶数组的指针,用于渐进式搬迁
nevacuate uintptr // 扩容进度计数器,表示旧桶中下一个要搬迁的桶的索引
// ... 其他字段
}
2. bmap (The Bucket)
bmap 就是哈希桶。与 Java 的 HashMap 不同,Go 的桶不是一个链表头,而是一个固定大小的、可以存放 8 个键值对的容器。
// A bucket for a Go map.
type bmap struct {
// tophash 存储了每个key的哈希值的高8位
tophash [8]uint8
// keys, values 和 overflow 字段在编译时会根据map的具体类型确定
// keys [8]keytype
// values [8]valuetype
// overflow *bmap
}关键点:
tophash: 这是 Gomap的一个核心优化。它存储了每个 key 计算出的哈希值的高 8 位。在查找时,可以先快速比较这 8 个tophash值,而不需要比较完整的、可能很长的 key。这极大地加速了在桶内的查找过程。- 连续内存:
bmap内部的keys和values是分开存放的。[8]keytype和[8]valuetype都是连续的内存块。这有助于提高 CPU 缓存的命中率,尤其是在 key 和 value 大小不同时。
桶数组和哈希冲突
1. 哈希桶数量的对数 B 是什么?
B 是一个非常巧妙的设计,它代表了哈希桶数量的以 2 为底的对数。
- 桶的数量:
num_buckets = 2^B - 作用: 它的主要作用是快速计算桶的索引。
要确定一个 key 应该放在哪个桶里,标准的做法是 hash(key) % num_buckets。但是,取模(%)运算在计算机中通常比位运算要慢。
因为 Go map 的桶数量永远是 2 的幂(2^B),所以取模运算可以被优化成一个位与(&)运算。
hash(key) % 2^B 等价于 hash(key) & (2^B - 1)
例如,如果 B=5,那么桶的数量就是 2^5 = 32。要找桶的索引,就是用 hash(key) & (32 - 1),即 hash(key) & 31。这相当于取哈希值的低 5 位。这个操作只需要一条 CPU 指令,非常高效。
所以,B 的存在,就是为了将取模运算优化为更快的位运算。
2. Go 中如何解决哈希冲突?
当多个不同的 key 经过哈希计算后,得到了相同的桶索引,就发生了哈希冲突。Go 通过以下两个机制来解决:
-
桶内槽位 (
tophash和key比较):- 一个
bmap内部有 8 个槽位。当一个 key 被映射到一个桶时,它会首先尝试在这 8 个槽位中找一个空位。 - 查找时,会遍历这 8 个槽位,先比较
tophash(哈希值的高 8 位)。如果tophash匹配,再进行完整的key比较,以确认是同一个 key(因为不同的 key 也可能有相同的tophash)。
- 一个
-
溢出桶 (Overflow Bucket):
- 如果一个
bmap的 8 个槽位都满了,此时又有新的 key-value 要存入,Go 运行时会创建一个新的bmap,我们称之为“溢出桶”。 - 然后,原来的桶的
overflow指针会指向这个新的溢出桶。 - 这样,当一个桶满了之后,它就形成了一个桶的链表。
- 查找时,如果在第一个桶里没找到,就会顺着
overflow指针去下一个溢出桶里继续查找。
- 如果一个
总结:Go 的冲突解决方案是 拉链法,但它的“链”的单位是桶(bmap),而不是像 Java 那样以单个节点为单位。
常见操作的底层实现
假设我们有 m := make(map[string]int)。
1. 查找 (value := m["key"])
- 哈希计算: Go 运行时根据
string类型选择一个哈希函数,并结合hmap.hash0(哈希种子)计算出"key"的哈希值。 - 定位桶: 使用哈希值的低
B位来确定它属于哪个桶,得到桶的地址。 - 桶内查找:
a. 提取哈希值的高 8 位作为
tophash。 b. 遍历当前桶的tophash数组,寻找与目标tophash匹配的槽位。 c. 如果tophash匹配,就比较该槽位存储的完整key是否与"key"相等。 d. 如果key也相等,则找到了目标,返回该槽位对应的value。 - 遍历溢出桶: 如果在当前桶中遍历完 8 个槽位都没有找到,就检查
overflow指针是否为nil。如果不为nil,就跳转到溢出桶,重复第 3 步。 - 处理扩容: 如果
map正在扩容(oldbuckets不为nil),查找逻辑会更复杂,需要同时检查新旧两个桶数组。 - 未找到: 如果遍历完所有相关的桶(包括溢出桶)都没有找到,返回
value类型的零值(对于int就是0)。
2. 增加或修改 (m["key"] = 100)
- 查找过程: 流程与“查找”操作的前半部分完全一样,目的是确定这个
key是否已经存在。 - 如果 Key 存在: 直接更新该
key所在槽位的value为100。操作结束。 - 如果 Key 不存在:
a. 在主桶和其溢出桶链中寻找一个空闲槽位。
b. 找到空闲槽位后,将
tophash、"key"和100分别存入该槽位的tophash、keys和values数组中。 c.hmap.count加 1。 d. 如果找不到空闲槽位(所有桶都满了),就创建一个新的溢出桶,链接到链表末尾,并将新的键值对存入新溢出桶的第一个槽位。 - 检查是否需要扩容: 每次成功插入新元素后,都会检查装载因子 (
load factor = count / 2^B)。如果装载因子超过阈值(当前是 6.5),就会触发一次扩容 (hashGrow)。
3. 删除 (delete(m, "key"))
- 查找过程: 同样,先执行查找操作定位到
key所在的槽位。 - 如果 Key 不存在:
delete操作直接返回,什么也不做。 - 如果 Key 存在:
a. 将该槽位中的
key和value清零(设置为类型的零值),以便垃圾回收器可以回收它们。 b. 将该槽位的tophash值设置成一个特殊的状态emptyOne。这个状态表示“这个槽位是空的,但这个桶的后面可能还有溢出桶,查找时请不要停下来”。 c.hmap.count减 1。 d. 注意: Go 的map在删除元素后不会自动缩容。桶数组的大小不会改变,只会将槽位标记为空。
结构体-自定义数据类型
结构体是Go语言中一种重要的自定义数据类型,它允许我们将多个不同类型的字段(Fields)聚合在一起,形成一个逻辑上的整体。这类似于C语言的 struct 或其他面向对象语言中的“类”(但Go的 struct 更轻量)。
- 聚合数据:将相关的数据字段组织在一起,如一个
User结构体可以包含Name,Email,Age等字段。 - 值类型:与数组一样,结构体也是值类型。赋值或作为函数参数传递时,会创建整个结构体的副本。
- 构建复杂类型的基础:结构体是构建更复杂数据模型和实现面向对象编程风格的基础。
声明和初始化
package main
import "fmt"
// 1. 定义一个结构体类型
type Person struct {
Name string // 导出的字段(首字母大写)
Age int
email string // 未导出的字段(仅包内可见)
}
func main() {
// 2. 初始化方式一:使用字段名(推荐,更清晰)
p1 := Person{
Name: "Alice",
Age: 30,
email: "[email protected]",
}
// 3. 初始化方式二:按顺序提供值(不推荐,易出错)
p2 := Person{"Bob", 25, "[email protected]"}
// 4. 创建指向结构体的指针 (常用)
p3 := &Person{Name: "Charlie", Age: 35}
// 5. 创建零值结构体
var p4 Person // 所有字段都是其类型的零值
fmt.Printf("p1: %+v\n", p1)
fmt.Printf("p2: %+v\n", p2)
fmt.Printf("p3 (pointer): %+v\n", *p3)
fmt.Printf("p4 (zero value): %+v\n", p4)
}
// 输出:
// p1: {Name:Alice Age:30 email:[email protected]}
// p2: {Name:Bob Age:25 email:[email protected]}
// p3 (pointer): {Name:Charlie Age:35 email:}
// p4 (zero value): {Name: Age:0 email:}Note: %+v 格式化占位符在打印结构体时非常有用,它会同时显示字段名和值。
访问和修改字段
通过 . 操作符来访问和修改结构体的字段。如果是一个指向结构体的指针,Go提供了语法糖,允许你直接使用 . 而无需解引用。
p := Person{Name: "David", Age: 40}
// 访问字段
fmt.Println(p.Name) // 输出: David
// 修改字段
p.Age = 41
// 对于指针
ptr_p := &p
fmt.Println(ptr_p.Name) // Go自动解引用,等效于 (*ptr_p).Name
ptr_p.Age = 42
fmt.Printf("p: %+v\n", p) // 输出: p: {Name:David Age:42 email:}匿名字段与结构体嵌入
Go语言支持在结构体中嵌入其他结构体类型作为匿名字段(Embedded Fields),这提供了一种类似“继承”的组合机制。
package main
import "fmt"
type Address struct {
City, Country string
}
type Employee struct {
Name string
Age int
Address // 匿名字段,直接嵌入Address类型
}
func main() {
emp := Employee{
Name: "Eve",
Age: 28,
Address: Address{
City: "New York",
Country: "USA",
},
}
// 可以直接访问嵌入结构体的字段,如同它们是Employee自己的字段一样
fmt.Println(emp.City) // 输出: New York
fmt.Println(emp.Country) // 输出: USA
// 也可以通过类型名访问
fmt.Println(emp.Address.City) // 输出: New York
}Note: 结构体嵌入是Go实现代码复用和组合的重要方式,它比传统继承更灵活。
结构体标签
结构体标签 (Struct Tag) 是附加在结构体字段声明后的一串可选的、用反引号包围的字符串。它为字段提供了额外的信息,这些信息在程序运行时可以通过 反射(Reflection) 机制被读取。
它本身不是 Go 语言的核心语法,而是一种约定俗成的规范。Go 的编译器会记录下这些标签,但不会在编译时去解析或使用它们。真正使用这些标签的是一些特定的标准库(如 encoding/json)或第三方库(如 ORM 框架、配置解析库等)。
标签的通用格式是一个由空格分隔的 key:"value" 对列表:
`key1:"value1" key2:"value1,value2,option"`key: 通常是某个库或包的名字,用来标识这个标签是给谁看的。例如,json是给encoding/json包看的,gorm是给 GORM 框架看的。value: 是一个用双引号包围的字符串,其具体含义由对应的key和处理它的库来定义。值内部可以用逗号分隔来提供多个选项。
为什么需要结构体标签?
- 解耦与定制化: 它将 Go 结构体的内部表示(字段名、类型)与外部数据格式(如 JSON、XML、数据库列名)的表示解耦。可以在不改变 Go 代码结构的前提下,灵活地定制其在不同格式下的表现。
- 提供元数据: 为字段提供了丰富的元数据,使得库可以基于这些元数据执行复杂的操作。例如,一个 ORM 框架可以这样使用标签:
这里,go
type User struct { ID int `gorm:"primaryKey;autoIncrement"` Name string `gorm:"column:user_name;size:255;not null"` }gorm标签告诉 GORM 框架ID是主键且自增,Name字段对应数据库中的user_name列,长度限制为255且不能为空。 - 保持代码清晰: 将这些配置信息直接附加在字段声明处,使得结构体的定义本身就成了“自解释”的文档,比在代码的其他地方进行配置要清晰得多。
make内置函数与nil标识符
make() 是Go语言的一个内置函数,其唯一的作用就是为切片、映射和通道这三种引用类型创建并初始化它们底层的、可用的数据结构。
| 类型 | make 语法 |
作用 |
|---|---|---|
| 切片 | make([]T, len, cap) |
创建一个底层数组,并返回一个引用该数组的切片,同时指定其初始长度和容量。 |
| 映射 | make(map[K]V, size) |
创建并初始化一个哈希表,使其可以开始存储键值对。size 是一个可选的性能提示。 |
| 通道 | make(chan T, capacity) |
创建一个用于goroutine间通信的通道。capacity决定了是无缓冲还是有缓冲通道。 |
make vs. new
| 特性 | make(T, ...) |
new(T) |
|---|---|---|
| 目的 | 初始化并分配切片、映射、通道这三种类型。 | 分配任意类型的内存,并将其清零。 |
| 返回值 | 返回一个已初始化的值,类型是 T (例如 []int, map[string]int)。 |
返回一个指向零值的指针,类型是 *T。 |
| 用法 | s := make([]int, 5) |
p := new(int) (p 的类型是 *int,*p 的值是 0) |
简单总结:
- 用
make来创建切片、映射和通道。 - 用
new来为任意类型分配内存,并获取一个指向该类型零值的指针。
在Go语言中,nil 是一个预定义的标识符,它代表了指针、接口、切片、映射、函数和通道这些类型的零值。
当一个引用类型的变量被声明但未初始化时,它的值就是 nil。一个 nil 值的变量意味着它没有指向任何有效的底层数据结构。
package main
import "fmt"
func main() {
var s []int // nil 切片
var m map[string]int // nil 映射
var p *int // nil 指针
fmt.Printf("切片s: %v, 是否为nil? %t\n", s, s == nil)
fmt.Printf("映射m: %v, 是否为nil? %t\n", m, m == nil)
fmt.Printf("指针p: %v, 是否为nil? %t\n", p, p == nil)
}
// 输出:
// 切片s: [], 是否为nil? true
// 映射m: map[], 是否为nil? true
// 指针p: <nil>, 是否为nil? trueCommon Pitfall:
nil切片和nil映射的行为差异 尽管切片和映射的零值都是nil,但它们对nil状态的操作表现不同,这是新手常见的困惑点。
nil切片 (Slice):
- 对一个
nil切片执行len()、cap()、for range或append操作都是完全安全的。Go语言将nil切片视作一个长度和容量都为0的空切片来处理。govar s []int // s is nil fmt.Println(len(s)) // 输出: 0 s = append(s, 1) // 安全!s现在是 [1] fmt.Println(s)
nil映射 (Map):
- 对一个
nilmap 执行len()、for range或读取操作是安全的(读取一个不存在的键会返回其值类型的零值)。- 但是,向一个
nilmap 写入数据会立即引发panic(运行时错误),因为没有为它分配底层的哈希表内存。govar m map[string]int // m is nil fmt.Println(len(m)) // 输出: 0 val := m["key"] // 安全!val是0 fmt.Println(val) // m["key"] = 1 // panic: assignment to entry in nil mapBest Practice:
- 对于切片,你可以直接开始使用
append,无需显式检查是否为nil。- 对于映射,在写入任何数据之前,必须确保它已经被
make初始化。