MySQL体系架构
MySQL体系架构
MySQL Server架构自顶向下大致可以分网络连接层、服务层、存储引擎层和系统文件层。
Connectors:与MySQL服务器建立连接。目前几乎支持所有主流的服务端编程技术,例如常见的 Java、C、Python、.NET等,它们通过各自API技术与MySQL建立连接
MySQL Server:服务层是MySQL的核心,主要包含系统管理和控制工具、连接池、SQL接口、解析器、查询优化器和缓存六个部分。
Pluggable Storage Engines:存储引擎负责MySQL中数据的存储与提取,与底层系统文件进行交互。MySQL存储引擎是插件式的,服务器中的查询执行引擎通过接口与存储引擎进行通信,接口屏蔽了不同存储引擎之间的差异 。现在有很多种存储引擎,各有各的特点,最常见的是MyISAM和InnoDB。在绝大多数情况下,推荐使用InnoDB
File System:该层负责将数据库的数据和日志存储在文件系统之上,并完成与存储引擎的交互,是文件的物理存储层。主要包含日志文件,数据文件,配置文件,pid 文件,socket 文件等。
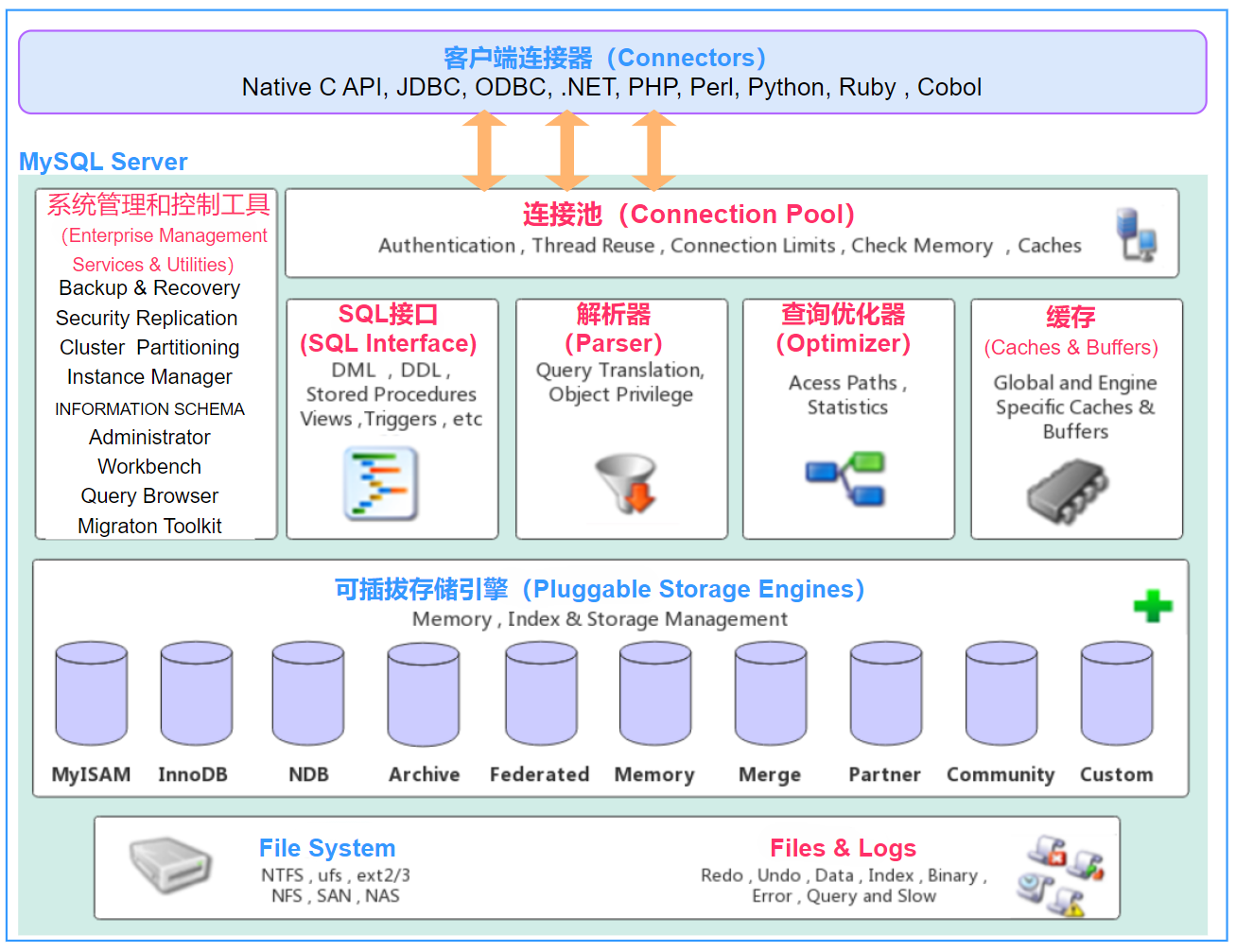
MySQL Server
连接池(Connection Pool):负责存储和管理客户端与数据库的连接。
系统管理和控制工具(Management Services & Utilities):如备份恢复、安全管理、集群管理等
SQL接口(SQL Interface):用于接受客户端发送的各种SQL命令,并且返回用户需要查询的结果。比如DML、DDL、存储过程、视图、触发器等。
解析器(Parser):负责将请求的SQL解析生成一个"解析树"。然后根据一些MySQL规则进一步检查解析树是否合法。
查询优化器(Optimizer):当“解析树”通过解析器语法检查后,将交由优化器将其转化成执行计划,然后与存储引擎交互。
缓存(Cache&Buffer): 缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,权限缓存,引擎缓存等。如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
File System
pid 文件: pid 文件是
mysqld应用程序在 Unix/Linux 环境下的一个进程文件,和许多其他 Unix/Linux 服务端程序一样,它存放着自己的进程 idsocket 文件: socket 文件也是在 Unix/Linux 环境下才有的,用户在 Unix/Linux 环境下客户端连接可以不通过
TCP/IP网络而直接使用 Unix Socket 来连接 MySQL。配置文件: 用于存放MySQL所有的配置信息文件,比如my.cnf、my.ini等。
数据文件
- db.opt 文件:记录这个库的默认使用的字符集和校验规则。
- frm 文件:存储与表相关的元数据(meta)信息,包括表结构的定义信息等,每一张表都会有一个
frm文件。 - MYD 文件:MyISAM 存储引擎专用,存放 MyISAM 表的数据(data),每一张表都会有一个
.MYD文件。 - MYI 文件:MyISAM 存储引擎专用,存放 MyISAM 表的索引相关信息,每一张 MyISAM 表对应一个
.MYI文件。 - ibd文件和 IBDATA 文件:存放 InnoDB 的数据文件(包括索引)。InnoDB 存储引擎有两种表空间方式:独享表空间和共享表空间。独享表空间使用
.ibd文件来存放数据,且每一张InnoDB 表对应一个.ibd文件。共享表空间使用.ibdata文件,所有表共同使用一个(或多个,自行配置).ibdata文件。 - ibdata1 文件:系统表空间数据文件,存储表元数据、Undo日志等 。
ib_logfile0、ib_logfile1文件:Redo log 日志文件。
日志文件:二进制日志(Binary Log)、慢查询日志(Slow query log)、通用查询日志(General query log)和错误日志(Error log)等。
Innodb存储引擎
从MySQL 5.5版本开始默认使用InnoDB作为引擎,它擅长处理事务,具有自动崩溃恢复的特性,在日常开发中使用非常广泛。
Architecture
下面是官方的InnoDB引擎架构图(MySQL5.7),MySQL8在磁盘结构方面有所不同。
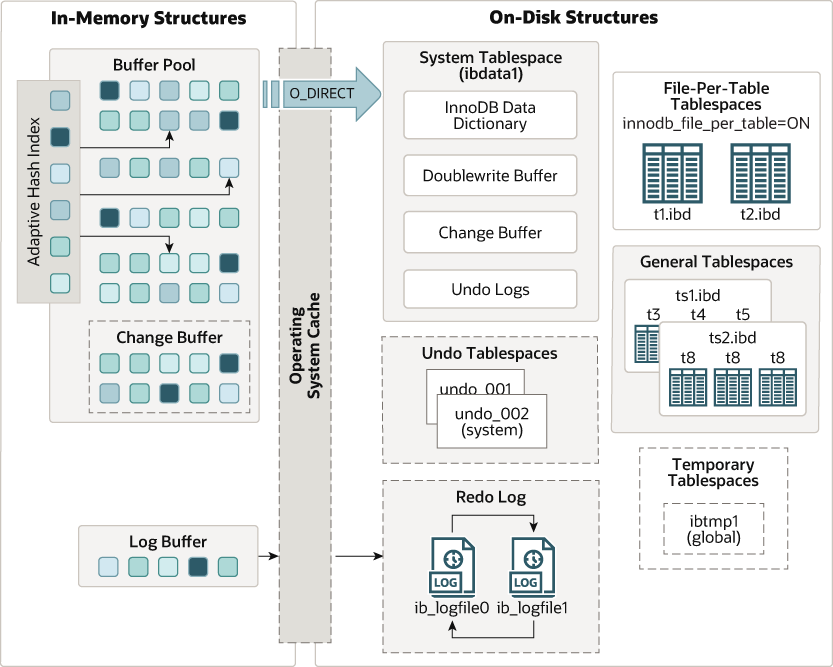
Innodb存储结构主要分为内存结构和磁盘结构两大部分
内存结构主要包括
Buffer Pool、Change Buffer、Adaptive Hash Index和Log BufferInnoDB磁盘主要包含
Tablespaces,InnoDB Data Dictionary,Doublewrite Buffer、Redo Log和Undo Logs
Buffer Pool
Buffer Pool:缓冲池,简称BP。BP以Page页为单位,BP的底层采用链表数据结构管理Page。访问表记录和索引时会在Page页中缓存,以后使用可以减少磁盘IO操作,提升效率
show variables like 'innodb_buffer_pool_size'; # 推荐设置为物理内存的 70% 到 80%
set global innodb_buffer_pool_size = 256 * 1024 * 1024; # MySQL5.7开始可以在线动态调整Page管理机制
缓冲池以Page页为单位,默认大小16K,底层采用链表数据结构管理Page。
show variables like '%innodb_page_size%'; # 查看page页大小根据状态,将Page分为三种类型:
- free page: 空闲page,未被使用。
- clean page: 未被使用page,数据没有被修改过
- dirty page: 脏页,被使用page,数据被修改过,内存数据与磁盘的数据产生了不一致。
针对上述三种page类型,InnoDB通过三种链表结构来维护和管理
- free list :表示空闲缓冲区,管理free page
- flush list:表示需要刷新到磁盘的缓冲区,管理dirty page,内部page按修改时间排序。
- lru list:表示正在使用的缓冲区,管理
clean page和dirty page,缓冲区以midpoint为基点,前面链表称为new列表区,存放经常访问的数据,占63%;后面的链表称为old列表区,存放使用较少数据,占37%。 (LRU:least recently used algorithm)
脏页即存在于flush链表,也在LRU链表中,但是两种互不影响,LRU链表负责管理page的可用性和释放,而flush链表负责管理脏页的刷盘操作。
缓冲池作为一个列表进行管理,使用了一种变体的 LRU 算法 -->a variation of the LRU algorithm

加入元素时并不是从表头插入,而是从中间midpoint位置插入,如果数据很快被访问,那么page就会向new列表头部移动,如果数据没有被访问,会逐步向old尾部移动,等待淘汰。
每当有新的page数据读取到buffer pool时,InnoDb引擎会判断是否有空闲页,是否足够,如果有就将free page从free list列表删除,放入到LRU列表中。没有空闲页,就会根据LRU算法淘汰LRU链表默认的页,将内存空间释放分配给新的页。
Change Buffer
Change Buffer:写缓冲区。在进行DML操作时,如果BP没有其相应的Page数据,并不会立刻将磁盘页加载到缓冲池,而是在CB记录缓冲变更,等未来数据被读取时,再将数据合并恢复到BP中。
ChangeBuffer占用BufferPool空间,默认占25%,最大允许占50%,可以根据读写业务量来进行调整。参数innodb_change_buffer_max_size;
写缓冲区为什么仅适用于非唯一普通索引页
如果索引具备唯一性,在进行修改时,InnoDB必须要做唯一性校验,因此必须查询磁盘,做一次IO操作。会直接将记录查询到BufferPool中,然后在缓冲池修改,不会在ChangeBuffer操作。
Adaptive Hash Index:自适应哈希索引,用于优化对BP数据的查询。InnoDB存储引擎会监控对表索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立哈希索引,所以称之为自适应。InnoDB存储引擎会自动根据访问的频率和模式来为某些页建立哈希索引。
InnoDB文件存储结构
InnoDB文件存储格式
Tablespaces
Select查询流程
Select执行流程: 一条SQL查询语句是如何执行的?
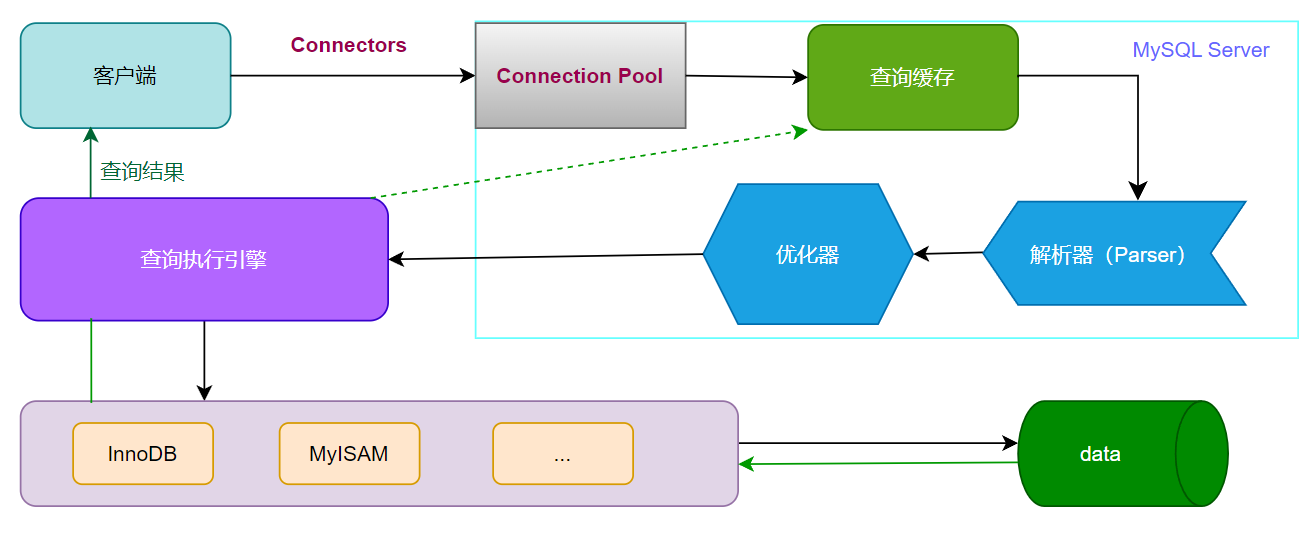
查询执行引擎负责执行 SQL 语句,查询执行引擎会根据 SQL 语句中表的存储引擎类型,以及对应的API接口与底层存储引擎缓存或者物理文件的交互,得到查询结果并返回给客户端。
若开启用查询缓存,这时会将SQL 语句和结果完整地保存到查询缓存(Cache&Buffer)中,以后若有相同的 SQL 语句执行则直接返回结果。
- 如果开启了查询缓存,先将查询结果做缓存操作
- 返回结果过多,采用增量模式返回
通讯机制与线程
通过客户端/服务器通信协议与MySQL建立连接(Connectors&Connection Pool)。MySQL 客户端与服务端的通信方式是 半双工。
通讯机制
- 全双工:能同时发送和接收数据,例如平时打电话。
- 半双工:指的某一时刻,要么发送数据,要么接收数据,不能同时。例如早期对讲机
- 单工:只能发送数据或只能接收数据。例如单行道
对于每一个 MySQL 的连接,时刻都有一个线程状态来标识这个连接正在做什么。
# 查看用户正在运行的线程信息,root用户能查看所有线程,其他用户只能看自己的
mysql> show processlist;
+----+-----------------+-----------+------+---------+------+------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+-----------+------+---------+------+------------------------+------------------+
| 5 | event_scheduler | localhost | NULL | Daemon | 139 | Waiting on empty queue | NULL |
| 9 | root | localhost | NULL | Query | 0 | init | show processlist |
+----+-----------------+-----------+------+---------+------+------------------------+------------------+
2 rows in set, 1 warning (0.00 sec)- id:线程ID,可以使用
kill xx; - user:启动这个线程的用户
- Host:发送请求的客户端的IP和端口号
- db:当前命令在哪个库执行
- Command:该线程正在执行的操作命令
- Create DB:正在创建库操作
- Drop DB:正在删除库操作
- Execute:正在执行一个PreparedStatement
- Close Stmt:正在关闭一个PreparedStatement
- Query:正在执行一个语句
- Sleep:正在等待客户端发送语句
- Quit:正在退出
- Shutdown:正在关闭服务器
- Time:表示该线程处于当前状态的时间,单位是秒
- State:线程状态
- Updating:正在搜索匹配记录,进行修改
- Sleeping:正在等待客户端发送新请求
- Starting:正在执行请求处理
- Checking table:正在检查数据表
- Closing table : 正在将表中数据刷新到磁盘中
- Locked:被其他查询锁住了记录
- Sending Data:正在处理Select查询,同时将结果发送给客户端
- Info:一般记录线程执行的语句,默认显示前100个字符。想查看完整的使用
show full processlist;
更多信息参照:MySQL8 show-processlist
查询缓存
如果开启了查询缓存且在查询缓存过程中查询到完全相同的SQL语句,则将查询结果直接返回给客户端;如果没有开启查询缓存或者没有查询到完全相同的 SQL 语句则会由解析器进行语法语义解析,并生成“解析树”。
show variables like '%query_cache%'; # 查看查询缓存是否启用,空间大小,限制等
show status like 'Qcache%'; # 查看更详细的缓存参数,可用缓存空间,缓存块,缓存多少等
SET GLOBAL query_cache_type = DEMAND; # 不建议使用查询缓存或者可以在 MySQL 的配置文件(通常是 my.cnf 或 my.ini)中设置:
[mysqld]
query_cache_type = DEMANDMySQL缓存的作用和注意事项
- 缓存Select查询的结果和SQL语句
- 执行Select查询时,先查询缓存,判断是否存在可用的记录集,要求是否完全相同(包括参数值),这样才会匹配缓存数据命中。
- 即使开启查询缓存,以下情形也不能缓存
- 查询语句使用
SQL_NO_CACHE - 查询的结果大于
query_cache_limit设置 - 查询中有一些不确定的参数,比如
now()
- 查询语句使用
注意,MySQL 8.0 版本直接将查询缓存的整块功能删掉了。
为什么 MySQL8.0 版本中移除了查询缓存功能
查询缓存的初衷是通过缓存完整的 SQL 查询结果来加速相同查询的执行。但其设计存在以下问题:
(1)缓存粒度过大
- 查询缓存存储的是完整的查询结果,对同一表的所有查询操作都没有区分更新粒度。
- 一旦表中的数据发生任何修改(包括
INSERT、UPDATE、DELETE等操作),所有涉及该表的缓存结果都会失效,无论修改是否影响缓存结果。这种机制在写操作频繁的场景中使查询缓存几乎没有命中率。
(2)缓存命中率低
- 查询缓存只能命中完全相同的 SQL 查询(包括大小写、空格等细微差异)。
- 如果查询带有动态条件(如时间戳或随机数),几乎不可能命中缓存。
(3)更新和维护开销高
- 查询缓存不仅需要占用内存,且需要在每次表更新时对相关缓存条目进行清理,这会引入额外的锁开销。
- 在高并发写入场景中,频繁的缓存失效和清理操作会导致严重的性能瓶颈。且限制了其在多核 CPU 和分布式场景下的扩展性。
移除查询缓存后,推荐使用 InnoDB 缓冲池 和 外部缓存系统(如 Redis) 来优化查询性能,以满足现代应用的需求。
解析器和优化器
解析器(Parser) 将客户端发送的SQL进行语法解析,生成 "解析树"。 预处理器根据一些MySQL规则进一步检查“解析树”是否合法,例如这里将检查数据表和数据列是否存在,还会解析名字和别名,看看它们是否有歧义,最后生成新的“解析树”。
查询优化器(Optimizer) 根据“解析树”生成最优的执行计划。MySQL使用很多优化策略生成最优的执行计划,可以分为两类:静态优化(编译时优化)、动态优化(运行时优化)。
- 等价变换策略
- 5=5 and a>5 改成 a > 5
- a < b and a=5 改成b>5 and a=5
- 基于联合索引,调整条件位置等
- 优化count、min、max等函数
- InnoDB引擎min函数只需要找索引最左边
- InnoDB引擎max函数只需要找索引最右边
- MyISAM引擎count(*),不需要计算,直接返回
- 提前终止查询: 使用了limit查询,获取limit所需的数据,就不在继续遍历后面数据
- in的优化: MySQL对in查询,会先进行排序,再采用二分法查找数据。比如where id in (2,1,3),变成 in (1,2,3)
Update流程与日志机制
WAL技术
缓冲池(Buffer Pool): 是主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删改查操作时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),然后再以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度。
如果缓存的内容更新好了,但磁盘的内容还是旧的,何时更新到磁盘呢?如何保证数据一致性呢?
WAL(Write-Ahead Logging)
WAL 技术:先写日志,再刷入磁盘。保证每个更新请求都是更新内存Buffer Pool,然后顺序写日志文件,同时还能保证各种异常情况下的数据一致性。
- 先写日志:记录
undo log和Redo Log日志文件(顺序写)- redo log称为重做日志,每当有操作时,在数据变更之前将操作写入redo log,这样当发生掉电之类的情况时系统可以在重启后继续操作。(事务的持久性)
- undo log又称为撤销日志,当一些变更执行到一半无法完成时,可以根据撤销日志恢复到变更之间的状态。(事务的原子性)
- 再刷入磁盘:将
Buffer Pool中的脏页写入磁盘(随机写)
为什么Mysql不能直接更新磁盘上的数据, 而设置这么一套复杂的机制来执行SQL了?
- InnoDB是以页为单位来进行磁盘IO的, 一个微小的更新就刷新一个完整的数据页到磁盘太浪费了
- 随机IO刷起来比较慢, Redo Log 的顺序写减少了随机 I/O,对传统机械硬盘性能提升显著。
Update更新流程
更新语句不但需要先查询,且在更新执行流程中,日志的写入和两阶段提交机制至关重要,它们确保了事务的持久性和一致性。
update table_name set a=a+1 where id=2加载数据页到缓冲池(Buffer Pool): 根据更新条件查找目标记录。
- 如果目标记录所在的数据页不在缓冲池中,从磁盘加载到缓冲池。
- 如果已经在缓冲池中,则直接操作。
- 目标记录所在的数据页被加锁(如行锁或间隙锁,具体取决于事务隔离级别)。
记录 Undo Log(用于回滚和 MVCC): 在对记录进行更新之前,生成 Undo Log 并存储在回滚段中,记录被修改前的旧值。Undo Log 用于支持
事务回滚(回退到原始状态)和多版本并发控制(MVCC)的一致性读。更新缓冲池中的数据: 修改缓冲池中的目标数据页,将数据标记为“脏页”(Dirty Page)。 数据尚未同步到磁盘,只是更新了内存中的缓存。
记录 Redo Log(日志缓冲区): 将更新操作写入 Redo Log Buffer(内存中的日志缓冲区),以物理日志的形式记录“对哪些数据页进行了哪些更改”。Redo Log Buffer 不会立即写入磁盘,而是由以下规则触发写入:
- 当事务进入 Prepare 阶段。
- 当 Redo Log Buffer 的使用量达到阈值(由
innodb_log_buffer_size控制)。 - 每秒的后台刷新(默认由
innodb_flush_log_at_trx_commit参数控制)。
Redo Log 的 Prepare 阶段: Redo Log Buffer 的内容被顺序写入磁盘(Redo Log 文件),并标记为“Prepare”状态。 此阶段的关键点:
- 确保数据的持久性:一旦系统崩溃,Redo Log 中的记录可以用来恢复到 Prepare 阶段的状态。
- 事务尚未提交,对外仍不可见。
记录 Binlog(逻辑日志): Server 层生成 Binlog 日志(逻辑日志),记录 SQL 语句的操作。 Binlog 被写入 Binlog Buffer(日志缓冲区),然后按照事务提交时的策略(
sync_binlog参数)决定是否同步到磁盘。sync_binlog=1:每次事务提交时将 Binlog 从缓冲区刷到磁盘,确保持久性。sync_binlog>1:延迟同步,可能丢失部分 Binlog。
Redo Log 的 Commit 阶段: 事务进入 Commit 阶段,Redo Log 文件中写入一个Commit 标记。Commit 标记表示事务提交完成,数据对外可见。Redo Log 的 Commit 标记同步到磁盘后,事务才算真正完成。
数据最终写入磁盘(刷脏页): 更新操作只修改缓冲池中的数据页,实际数据页的写入由后台线程完成(异步操作)。 脏页刷盘的触发条件:
- 缓冲池使用率达到阈值(由
innodb_max_dirty_pages_pct控制)。 - Redo Log 的空间不足。
- 手动触发(如执行
FLUSH操作)。
- 缓冲池使用率达到阈值(由
两阶段提交(内部XA)
两阶段提交(2PC)在 Redo Log 和 Binlog 的协调中起到核心作用,确保两者一致性。
- Prepare 阶段: Redo Log 的 Prepare 状态在 Binlog 写入之前完成。 即使系统崩溃,只要有 Redo Log 的 Prepare 日志,数据仍可以恢复到一致性状态。
XA事务--extra disk flush for transaction preparation
MySQL官方文档明确指出了在 XA 事务的两阶段提交过程中,prepare 阶段也会涉及到磁盘刷新操作。详见:innodb_support_xa
禁用 innodb_support_xa 可能会导致复制不安全,因此MySQL禁止了与二进制日志组提交相关的性能提升,这也是为什么从 MySQL 5.7.10 版本开始,这个功能始终是开启的,不允许再禁用。
Binlog 写入: Binlog 写入成功后,再进入 Redo Log 的 Commit 阶段。 确保 Binlog 和 Redo Log 的位置(LSN)一致。
Commit 阶段: Redo Log 写入 Commit 标记,表示事务完成。 若系统崩溃后只找到 Prepare 状态的 Redo Log,事务会被回滚(保证一致性)。
Redo Log -- 崩溃恢复(自动恢复机制)
MySQL 的恢复过程是完全自动的,发生在实例启动时(启动时崩溃恢复):
- MySQL 检查 InnoDB 的事务日志(Redo Log)和 Server 层的 Binlog。
- 根据 Redo Log 的 Prepare 和 Commit 状态确定事务的完成情况。
- 未提交的事务会被回滚,已提交的事务会通过重放日志恢复。
(1)事务未完成(未提交):
如果事务在 Commit 阶段之前(Redo Log 还处于 Prepare 状态),MySQL 会自动回滚该事务:使用 Undo Log 回滚事务,将数据恢复到事务开始之前的状态。
(2)事务已提交:
如果事务已经完成 Commit 阶段(Redo Log 有 Commit 标记),但尚未将数据页刷回磁盘,MySQL 会通过 Redo Log 自动重做事务:通过读取 Redo Log,将事务对应的数据修改重新应用到数据页(即使数据页尚未写入磁盘)。
(3)结合 Binlog 和 Redo Log 的一致性恢复:
对于绝大多数场景,恢复过程是全自动的,但建议定期备份数据以应对极端情况。
关键参数的提示和优化
innodb_flush_log_at_trx_commit: 控制 Redo Log 的刷盘策略:1:每次事务提交时刷盘,提供最高的数据安全性。0:不实时刷盘,性能高但可能丢失数据。2:事务提交时写入 OS 缓冲区,定时刷盘。
sync_binlog: 控制 Binlog 的刷盘策略:1:每次事务提交时同步到磁盘,确保 Binlog 的持久性。- 较大的值(如
100)可以提高性能,但可能丢失最近的事务日志。
innodb_log_buffer_size: 增大日志缓冲区可以减少磁盘 I/O,但过大可能浪费内存。
总结
- MySQL 自动恢复数据:当机器断电或崩溃时,MySQL 会根据 Redo Log 和 Binlog 自动恢复事务,确保数据一致性和持久性。
- 两阶段提交保障一致性:通过两阶段提交机制,确保 Redo Log 和 Binlog 的一致性,无需手动介入。
- 建议启用安全参数:如
innodb_flush_log_at_trx_commit=1和sync_binlog=1,以最大程度减少数据丢失风险。
Redo Log
Redo Log 是物理增量日志,核心在于持久性、性能优化和崩溃恢复。
- 持久性保证(Durability): 确保事务的修改在提交前已写入日志,即使系统崩溃也能恢复。
- 崩溃恢复: 万一断电或者数据库挂了,在重启时根据redo日志中的记录就可以将数据自动恢复。
Redo Log 文件
- 日志条目结构: 包括事务 ID、数据页编号、页偏移量、修改内容等信息。
- 文件组成: Redo Log 由多个日志文件组成(如
ib_logfile0、ib_logfile1,默认为 2 个, 位于 MySQL 数据目录中),以环形方式写入
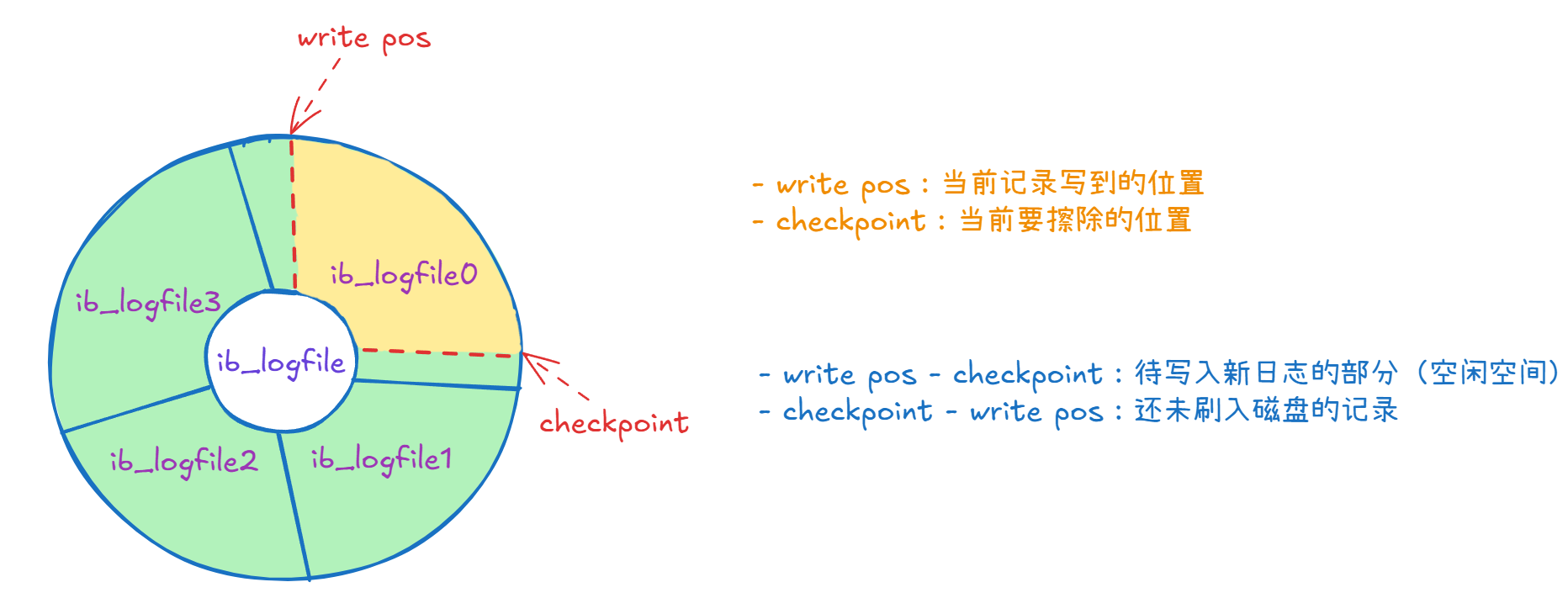
- write pos(写入位置)表示当前日志写入的位置。随着事务执行,write pos 向前移动。
- 只有对应日志刷入数据文件(即数据页写入磁盘)后,checkpoint 才能推进。
如果 write pos 追上了 checkpoint,说明环形日志空间已满,MySQL 暂时停止写入。此时应该推进 checkpoint,擦除已刷入磁盘的数据日志,释放更多空间。
从 MySQL 8.0 开始,Redo Log 文件有所变化:/var/lib/mysql/'#innodb_redo'/'#ib_redo13'
show variables like '%innodb_log_group_home_dir%'; # ./ 数据目录
SHOW VARIABLES LIKE 'datadir'; # datadir /var/lib/mysql/相关参数及作用
show variables like '%innodb_log_file_size%';
show variables like '%innodb_log_files_in_group%';| 参数 | 作用 | 默认值 |
|---|---|---|
innodb_log_file_size | 每个 Redo Log 文件的大小,影响日志循环频率和崩溃恢复时间 | 48MB |
innodb_log_files_in_group | Redo Log 文件的数量,默认 2 个,组成环形日志组 | 2 |
innodb_log_buffer_size | Redo Log Buffer 的大小,较大的值减少刷盘频率(适合高事务量场景) | 16MB |
innodb_flush_log_at_trx_commit | 控制事务提交时日志刷盘的策略 | 1 |
innodb_flush_method | 控制日志和数据文件刷盘方式:如 O_DIRECT(跳过文件系统缓存)、fsync(默认)。 | fsync |
Redo Log刷盘时机由innodb_flush_log_at_trx_commit参数控制,详见:innodb-parameters
这里的刷盘指的是Redo Buffer -> OS cache -> flush cache to disk,fsync() 的作用就是强制将内核缓冲区中的数据写入到磁盘
- 1(default): 每次事务提交都执行刷盘,最安全,性能最差的方式
- 0:每秒执行一次刷盘,可能丢失一秒内的事务数据
- 2:每次事务提交执行
Redo Buffer -> OS cache,由后台Master线程每隔1秒调用fsync()
刷盘机制相关的性能优化
- 参数调优:
- 增大
innodb_log_file_size和innodb_log_buffer_size,减少日志切换和刷盘频率。 - 根据业务需求调整
innodb_flush_log_at_trx_commit(如设置为2提升性能)。
- 增大
- 硬件优化:
- 使用高速存储设备(如 NVMe SSD)提升刷盘速度。
- 为日志存储独立分区,避免与数据文件竞争 I/O。
- 批量事务: 合并多个小事务为一个大事务,降低日志写入频率。
Binlog
Binary log(二进制日志),简称Binlog(MySQL Server自己的日志)。Binlog是记录所有数据库表结构变更以及表数据修改的二进制日志,不会记录SELECT和SHOW这类操作。Binlog日志是以事件形式记录,还包含语句所执行的消耗时间。开启Binlog日志有以下两个最重要的使用场景。
- 主从复制:在主库中开启Binlog功能,这样主库就可以把Binlog传递给从库,从库拿到Binlog后实现数据恢复达到主从数据一致性。
- 数据恢复:通过
mysqlbinlog工具来恢复数据。
show variables like 'log_bin'; # Binlog状态查看
show binary logs; # Binlog开启后可以查看有多少binlog文件MySQL5.7 版本中Binlog默认是关闭的,8.0版本默认是开启的。开启Binlog需要修改my.cnf或my.ini配置文件,然后重启MySQL服务。
[mysqld]
log_bin=/var/lib/mysql/mysql-binlog
binlog-format=ROW
server-id=1
expire_logs_days =30开启 Binlog 后,默认可以在数据目录查看到具体的 Binlog 文件:ls /var/lib/mysql/
topple@Ubuntu22:~$ ls /docker/mysql/mysql5.7/data/
auto.cnf client-key.pem ib_logfile1 mysql-bin.000001 mysql-binlog.000001 private_key.pem sys
ca-key.pem demo ibdata1 mysql-bin.000002 mysql-binlog.index public_key.pem
ca.pem ib_buffer_pool ibtmp1 mysql-bin.000003 mysql.sock server-cert.pem
client-cert.pem ib_logfile0 mysql mysql-bin.index performance_schema server-key.pem发生以下任何事件时, binlog日志文件会重新生成:
- 服务器启动或重新启动
- 服务器刷新日志,执行命令
flush logs - 日志文件大小达到
max_binlog_size值,默认值为 1GB
binlog-format(Binlog文件格式)
binlog_format 参数可以设置binlog日志的记录格式,详见:binlog_format
- ROW(row-based replication, RBR):日志中会记录每一行数据被修改的情况,然后在slave端对相同的数据进行修改。
优点:能清楚记录每一个行数据的修改细节,能完全实现主从数据同步和数据的恢复。
缺点:批量操作,会产生大量的日志,尤其是alter table会让日志暴涨。 - STATMENT(statement-based replication, SBR):每一条被修改数据的SQL都会记录到master的Binlog中,slave在复制的时候SQL进程会解析成和原来master端执行过的相同的SQL再次执行。简称SQL语句复制。
优点:日志量小,减少磁盘IO,提升存储和恢复速度
缺点:在某些情况下会导致主从数据不一致,比如last_insert_id()、now()等函数。 - MIXED(mixed-based replication, MBR):以上两种模式的混合使用,一般会使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择写入模式。
该参数在MySQL5.7.7默认值为STATEMENT. MySQL5.7.7及以后默认值为 ROW. 8.0.34中被弃用,未来可能会移除,默认使用ROW
sync_binlog(Binlog刷盘机制)
- 0(default): 表示每次提交事务都只 write 到
page cache,由系统自行判断什么时候执行fsync写入磁盘。虽然性能得到提升,但是机器宕机,page cache里面的 binlog 会丢失。 - 1:表示每次提交事务都会执行
fsync写入磁盘,这种方式最安全。 - N(N>1):表示每次提交事务都 write 到
page cache,但累积N个事务后才fsync写入磁盘,这种如果机器宕机会丢失N个事务的binlog。
关于MySQL的Binlog文件操作和数据恢复参照:mysqlbinlog
MySQL日志管理
MySQL 中的日志是数据库管理和故障恢复的重要组成部分。包括二进制日志(Binary Log)、重做日志(Redo Log)、回滚日志(Undo Log)等。
- 二进制日志(Binary Log):记录所有更改操作,用于数据恢复和主从复制。
- 重做日志(Redo Log):记录事务的更改,用于事务持久性和崩溃恢复。
- 回滚日志(Undo Log):记录事务开始时的数据快照,用于事务回滚和MVCC(多版本并发控制)
- 错误日志(Error Log):记录服务器的错误和警告信息。
- 慢查询日志(Slow Query Log):记录执行时间超过阈值的查询语句。
- 查询日志(General Query Log):记录所有客户端发送的查询语句。
二进制日志记录了所有对数据库的更改操作,包括数据修改(如 INSERT、UPDATE、DELETE)和结构修改(如 CREATE、ALTER)。这些日志以二进制格式存储,主要用于数据恢复、主从复制和审计。
在 MySQL 配置文件(通常是 my.cnf 或 my.ini)中启用二进制日志:
[mysqld]
log_bin = /path/to/binlog/mysql-bin.log
server_id = 1清除旧的二进制日志:
PURGE BINARY LOGS TO 'mysql-bin.000005';
PURGE BINARY LOGS BEFORE '2023-10-01 00:00:00';重做日志是 InnoDB 存储引擎特有的日志,用于实现事务的持久性和崩溃恢复。每次事务提交时,InnoDB 会将事务的更改记录到重做日志中。如果数据库发生崩溃,可以通过重做日志恢复未完成的事务。
重做日志的配置参数包括日志文件的数量和大小:
[mysqld]
innodb_log_file_size = 512M
innodb_log_files_in_group = 2初始化或更改重做日志大小:需要先关闭 MySQL 服务,删除现有的重做日志文件,然后重新启动 MySQL 服务。
systemctl stop mysql
rm -f /var/lib/mysql/ib_logfile*
systemctl start mysql回滚日志也是 InnoDB 存储引擎特有的日志,用于实现事务的回滚和多版本并发控制(MVCC)。每个事务开始时,InnoDB 会记录事务开始时的数据快照,以便在事务回滚或读取历史版本数据时使用。回滚日志的配置参数包括日志段的数量和大小:
[mysqld]
innodb_undo_tablespaces = 2
innodb_undo_logs = 128回滚日志的空间管理:长时间运行的事务可能会导致回滚日志空间占用过大,可以通过调整 innodb_max_undo_log_size 参数来控制最大回滚日志大小。
错误日志记录了 MySQL 服务器的错误信息、警告信息和启动信息。这些信息对于诊断和解决数据库问题非常有用。
在 MySQL 配置文件中启用错误日志:
[mysqld]
log_error = /path/to/error.log- 查看错误日志:
cat /path/to/error.log show variables like '%log_error%'
慢查询日志记录了执行时间超过指定阈值的查询语句。这些日志有助于识别和优化性能瓶颈。
在 MySQL 配置文件中启用慢查询日志:
[mysqld]
slow_query_log = 1
slow_query_log_file = /path/to/slow-query.log
long_query_time = 2查看慢查询日志:
show variables like '%slow_query%'; # 是否开启 show variables like '%long_query_time%'; # 时长 cat /path/to/slow-query.log动态启用或禁用慢查询日志:
SET GLOBAL slow_query_log = 'ON'; SET GLOBAL slow_query_log = 'OFF';
查询日志记录了所有客户端发送到服务器的查询语句。这些日志对于调试和审计非常有用。
在 MySQL 配置文件中启用查询日志:
[mysqld]
general_log = 1
general_log_file = /path/to/general-query.log查看查询日志:
cat /path/to/general-query.log动态启用或禁用查询日志:
SET GLOBAL general_log = 'ON'; SET GLOBAL general_log = 'OFF'; show variables like '%general%';