Java数组和字符串
Java数组和字符串
一 数组(array)
数组是相同数据类型的多个数据的容器,这些元素按线性顺序排列。
所谓线性顺序是指除第一个元素外,每一个元素都有唯一的前驱元素;除最后一个 元素外,每一个元素都有唯一的后继元素
int[] arr1; // java数组
int arr2[]; // C/C++风格数组下标:对于长度为 n 的数组,下标的范围是 0 ~ n-1
1. 数组初始化
Java语言是典型的静态语言,因此Java数组是静态的,即当数组被初始化之后,该数组所占的内存空间、数组长度都是不可变的。
Java程序中的数组必须经过初始化才可使用。
所谓初始化,即创建实际的数组对象,也就是在内存中为数组对象分配内存空间,并为每个数组元素指定初始值。
数组的初始化有以下两种方式:
➢ 静态初始化:初始化时由程序员显式指定每个数组元素的初始值,由系统决定数组长度。
➢ 动态初始化:初始化时程序员只指定数组长度,由系统为数组元素分配初始值。
不管采用哪种方式初始化数组,一旦初始化完成,该数组的长度就不可改变,Java语言允许通过数组的length属性来访问数组的长度。
// 数组的创建和初始化:
int[] arr1 = {1,2,3,4,5}; // 静态初始化
int[] arr2 = new int[100]; // 动态初始化 初始值全为0(boolean 则为false , 对象为 null ......)
arr2 = new int[]{12,33,21,43,22,45}; // 初始化一个匿名数组并赋值给 arr2记住:Java的数组变量只是引用类型的变量,它并不是数组对象本身,只要让数组变量指向有效的数组对象,程序中即可使用该数组变量。当数组引用变量指向一个有效的数组对象之后,程序就可以通过该数组引用变量来访问数组对象。
注意事项
在使用Java数组之前必须先进行初始化!但注意不要把数组变量和数组对象搞混了,数组变量只是一个引用变量(有点类似于C语言里的指针);
而数组对象就是保存在堆内存中的连续内存空间。
对数组执行初始化,其实并不是对数组变量执行初始化,而是在堆内存中创建数组对象——也就是为该数组对象分配一块连续的内存空间,这块连续的内存空间的长度就是数组的长度。
Java程序中的引用变量并不需要经过所谓的初始化操作,需要进行初始化的是引用变量所引用的对象。比如,数组变量不需要进行初始化操作,而数组对象本身需要进行初始化;对象的引用变量也不需要进行初始化,而对象本身才需要进行初始化。
需要指出的是,Java的局部变量必须由程序员提供初始值,因此如果定义了局部变量的数组变量,程序必须对局部的数据变量进行赋值,即使将它赋值为null也行。
注意:有些书中总是不断地重复:基本类型变量的值被存储在栈内存中,其实这句话是完全错误的。例如数组中的基本数组类型,它们都是基本类型的值,但实际上它们却被存储在堆内存中。
实际上应该说:所有局部变量都是放在栈内存里保存的,不管其是基本类型的变量,还是引用类型的变量,都是存储在各自的方法栈内存中的;但引用类型的变量所引用的对象(包括数组、普通的Java对象)则总是存储在堆内存中。
2. 排序和查找
冒泡排序(Bubble Sort):
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数
- 针对所有的元素重复以上的步骤,除了最后一个
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较
升序排列的口诀: N个数字来排队、 两两相比小靠前、外层 循环length-1、 内层循环length-i-1
降序排序的口诀: N个数字来排队、 两两相比大靠前、 外层 循环length-1、 内层循环length-i-1
二分查找(Binary Search):
二分查找也称折半查找,它是一种效率较高的查找方法。但是,二分查找要求数组数据必须采用顺序存储结构有序排列
- 首先,假设数组中元素是按升序排列,将数组中间位置的数据与查找数据比较,如果两者相等,则查找成功;否则利用 中间位置记录将数组分成前、后两个子数组,如果中间位置数据大于查找数据,则进一步查找前子数组,否则进一步查 找后子数组
- 重复以上过程,直到找到满足条件的数据,则表示查找成功, 直到子数组不存在为止,表示查找不成功
/**
* 排序并查找 对数组{1,3,9,5,6,7,15,4,8}进行排序,然后使用二分查找元素 6 并输出排序后的下标。
*/
public class ArrayDemo {
public static void main(String[] args) {
int[] nums = { 1, 3, 9, 5, 6, 7, 15, 4, 8 };
// Bubble Sort
for (int i = 0; i < nums.length - 1; i++) {
for (int j = 0; j < nums.length - i - 1; j++) {
if (nums[j] > nums[j + 1]) {
nums[j] = nums[j] ^ nums[j + 1];
nums[j + 1] = nums[j] ^ nums[j + 1];
nums[j] = nums[j] ^ nums[j + 1];
}
}
}
System.out.println("排序后的数组:" + Arrays.toString(nums));
// 使用 Binary Search 查找元素 6
int target = 6;
int minIndex = 0;
int maxIndex = nums.length;
int centreIndex = (minIndex + maxIndex) / 2;
while (true) {
if (minIndex > maxIndex) {
System.out.println("Not found!");
break;
}
if (target < nums[centreIndex]) {
maxIndex = centreIndex - 1;
} else if (target > nums[centreIndex]) {
minIndex = centreIndex + 1;
} else {
System.out.println(target + "的下标为:" + centreIndex);
break;
}
centreIndex = (minIndex + maxIndex) / 2;
}
}
}3. 关于多维数组
所谓多维数组,其实就是数组元素依然是数组的一维数组,
二维数组是数组元素是一维数组的数组,三维数组是数组元素是二维数组的数组……N维数组是数组元素是N-1维数组的数组。
即多维数组的本质依然是一维数组。
提示
只要在已有数据类型之后增加方括号,就会产生一个新的数组类型。
如果已有的类型是int,增加方括号后是int[]类型,这是一个数组类型;
如果再以int[]类型为已有类型,增加方括号后就得到int[][]类型,这依然是数组类型;
如果再以int[][]类型为已有类型,增加方括号后就得到int[][][]类型,这依然是数组类型。
反过来,将数组类型最后的一组方括号去掉就得到了数组元素的类型。
对于int[][][]类型的数组,其数组元素就相当于int[][]类型的变量;
对于int[][]类型的数组,其数组元素就相当于int[]类型的变量;
对于int[]类型的数组,其数组元素就相当于int类型的变量。
Java允许将多维数组当成一维数组处理。初始化多维数组时可以先只初始化最左边的维数,此时该数组的每个元素都相当于一个数组引用变量(但此时都是null),这些数组元素还需要进一步初始化。
// 使用示例
double[][] balances;
balances = new double[3][4]; // 将 balances 初始化为 0
int[][] magicSquare ={
{34, 44, 21, 44},
{22, 32, 11, 99},
{54, 33, 29, 84}};
System.out.println (Arrays.deepToString(magicSquare)); // 快速打印二维数组二 Arrays类
Java中有一个Arrays类,包含一些对数组操作的静态方法
1. toString
Arrays的toString()方法可以方便地输出一个数组的字符串形式,以便查看。
它有9个重载的方法,包括8个基本类型数组和1个对象类型数组
public static String toString(int[] a)
public static String toString(long[] a)
public static String toString(short[] a)
public static String toString(char[] a)
public static String toString(byte[] a)
public static String toString(boolean[] a)
public static String toString(float[] a)
public static String toString(double[] a) public static String toString(Object[] a) {
if (a == null)
return "null";
int iMax = a.length - 1;
if (iMax == -1)
return "[]";
StringBuilder b = new StringBuilder();
b.append('[');
for (int i = 0; ; i++) {
b.append(String.valueOf(a[i]));
if (i == iMax)
return b.append(']').toString();
b.append(", ");
}
}public static String deepToString(Object[] a) {
if (a == null)
return "null";
int bufLen = 20 * a.length;
if (a.length != 0 && bufLen <= 0)
bufLen = Integer.MAX_VALUE;
StringBuilder buf = new StringBuilder(bufLen);
deepToString(a, buf, new HashSet<Object[]>());
return buf.toString();
}2. 排序和查找
是一种非常常见的操作。同toString一样,对每种基本类型的数组,Arrays都有sort方法(boolean除外)
public static void sort(int[] a) {
DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0);
}除了基本类型,sort还可以直接接受对象类型,但对象需要实现Comparable接口。
// 对象需要实现Comparable接口
public static void sort(Object[] a) {
if (LegacyMergeSort.userRequested)
legacyMergeSort(a);
else
ComparableTimSort.sort(a, 0, a.length, null, 0, 0);
}
// 使用Comparator作为排序的比较规则
public static <T> void sort(T[] a, Comparator<? super T> c) {
if (c == null) {
sort(a);
} else {
if (LegacyMergeSort.userRequested)
legacyMergeSort(a, c);
else
TimSort.sort(a, 0, a.length, c, null, 0, 0);
}
}传递比较器Comparator给sort方法,体现了程序设计中一种重要的思维方式。将不变和变化相分离,排序的基本步骤和算法是不变的,但按什么排序是变化的,sort方法将不变的算法设计为主体逻辑,而将变化的排序方式设计为参数,允许调用者动态指定,这也是一种常见的设计模式,称为策略模式,不同的排序方式就是不同的策略
Arrays包含很多与sort对应的查找方法,可以在已排序的数组中进行二分查找。
所谓二分查找就是从中间开始查找,如果小于中间元素,则在前半部分查找,否则在后半部分查找,每比较一次,要么找到,要么将查找范围缩小一半,所以查找效率非常高。
public static int binarySearch(int[] a, int key) {
return binarySearch0(a, 0, a.length, key);
}二分查找既可以针对基本类型数组,也可以针对对象数组,对对象数组,也可以传递Comparator,也可以指定查找范围。
public static int binarySearch(Object[] a, Object key) {
return binarySearch0(a, 0, a.length, key);
}public static <T> int binarySearch(T[] a, int fromIndex, int toIndex, T key, Comparator<? super T> c) {
rangeCheck(a.length, fromIndex, toIndex);
return binarySearch0(a, fromIndex, toIndex, key, c);
}3. 更多方法
除了常用的toString、排序和查找,Arrays中还有复制、比较、批量设置值和计算哈希值等方法。
// 基于原数组,复制一个新数组,与toString一样,也有多种重载形式
public static byte[] copyOf(byte[] original, int newLength) {
byte[] copy = new byte[newLength];
System.arraycopy(original, 0, copy, 0, Math.min(original.length, newLength));
return copy;
}// 判断两个数组是否相同,支持基本类型和对象类型
public static boolean equals(int[] a, int[] a2) {
if (a==a2)
return true;
if (a==null || a2==null)
return false;
int length = a.length;
if (a2.length != length)
return false;
for (int i=0; i<length; i++)
if (a[i] != a2[i])
return false;
return true;
}
public static boolean equals(Object[] a, Object[] a2) {
if (a==a2)
return true;
if (a==null || a2==null)
return false;
int length = a.length;
if (a2.length != length)
return false;
for (int i=0; i<length; i++) {
Object o1 = a[i];
Object o2 = a2[i];
if (!(o1==null ? o2==null : o1.equals(o2)))
return false;
}
return true;
}// 针对数组,计算一个数组的哈希值:
public static int hashCode(int a[]) {
if (a == null)
return 0;
int result = 1;
for (int element : a)
result = 31 * result + element;
return result;
}
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}三 字符串(String)
Java中处理字符串的主要类是String、StringBuilder和StringBuffer
字符串可以通过常量定义String变量,也可以通过new创建String变量。如:
String name = "java";
String str = new String("java program");
// String可以直接使用 + 和 += 运算符,
name += "desc";1. String类
String类位于 java.lang 包中,在 Java 中每个双引号定义的字符串都是一个 String 类的对象。
String对象不可变:对象一旦被创建后,对象所有的状态及属性在其生命周期内不会发生任何变化,不可变的原因与本质:
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
}String的真实面目就是一个 final 修饰的 char 数组(即初始化后就不能再变了)
String 类的构造方法:
String() // 初始化一个新创建的 String对象,表示一个空字符序列 String(String original) // 初始化一个新创建的 String对象,新创建的字符串是该参数字符串的副本 String(char[] value) // 分配一个新的字符串,将参数中的字符数组元素全部复制变为字符串 String(char[] value,int offset,int count) //offset是数组第一个字符的索引,count指定子数组的长度需要说明的是,String会根据参数新创建一个数组,并复制内容,而不会直接用参数中的字符数组。
String中的大部分方法内部也都是操作的这个字符数组。
String和int的相互转换
// String 字符串转整型 int 有以下两种方式: Integer.parseInt(str) Integer.valueOf(str).intValue() // int转换为String String s = String.valueOf(i); String s = Integer.toString(i); String s = "" + i;String常用方法
length() :获取字符串的长度
toLowerCase() :将字符串中的所有字符全部转换成小写,而非字母的字符不受影响
toUpperCase() :将字符串中的所有字符全部转换成大写,而非字母的字符不受影响
trim() :去掉字符串中的首尾空格
substring(int beginIndex) :提取从索引位置开始至结尾处的字符串部分
substring(int beginIndex,int endIndex) :截取 [beginIndex,endIndex) 索引的字符串
String分割字符串
str.split(String sign) str.split(String sign,int limit)sign 为指定的分割符,可以是任意字符串。
limit 表示分割后生成的字符串的限制个数,如果不指定,则表示不限制,直到将整个目标字符串完全分割为止。
如果用“.”作为分隔的话,必须写成
String.split("\\."),这样才能正确的分隔开,不能用String.split(".")。如果用“|”作为分隔的话,必须写成
String.split("\\|"),这样才能正确的分隔开,不能用String.split("|")。如果在一个字符串中有多个分隔符,可以用
|作为连字符,比如:"acount=? and uu =? or n=?",需要把三个都分隔出来,可以用String.split("and|or")。
字符串查找
indexOf()方法用于返回字符(串)在指定字符串中首次出现的索引位置,如果能找到,则返回索引值,否则返回 -1lastIndexOf()方法用于返回字符(串)在指定字符串中最后一次出现的索引位置,如果能找到则返回索引值,否则返回 -1charAt()方法可以在字符串内根据指定的索引查找字符(字符串本质上是字符数组,因此它也有索引,索引从零开始)
字符串的替换
replace(String oldChar, String newChar) // 将目标字符串中的指定字符(串)替换成新的字符(串) replaceFirst(String regex, String replacement) // 将目标字符串中匹配某正则表达式的第一个子字符串替换成新的字符串 replaceAll(String regex, String replacement) // 将目标字符串中匹配某正则表达式的所有子字符串替换成新的字符串字符串比较
equals()方法将逐个地比较两个字符串的每个字符是否相同如果两个字符串具有相同的字符和长度,它返回 true,否则返回 false。( 区分大小写 )
equalsIgnoreCase()方法的作用和语法与 equals() 方法完全相同,但是不区分大小写equals()方法和==运算符:==运算符比较两个对象引用看它们是否引用相同的实例- equals() 原本也是比较引用是否相同,但String类重写了该方法,故而直接比较字符串对象中的字符
compareTo()方法用于按字典顺序比较两个字符串的大小,该比较是基于字符串各个字符的 Unicode 值
String str1 = new String("hello"); String str2 = new String("hello"); System.out.println(str1.equals(str2)); // true System.out.println(str1 == str2); // false System.out.println("a".compareTo("A")); // 32 ( 表示a在A之后32个字符序列 )
2. 字符串拼接
String 字符串虽然是不可变字符串,但也可以进行拼接只是会产生一个新的对象。
String 字符串拼接可以使用“+”运算符或 String 的 concat(String str) 方法。
+ 和 concat
“+” 运算符优势是可以连接任何类型数据拼接成为字符串,而 concat 方法只能拼接 String 类型字符串。
String str = "hello ";
System.out.println(str + 99); // hello 99
System.out.println(str.concat("world")); // hello worldconcat由于是内部机制实现,比+的方式好了不少(每次调用contact()方法就是一次数组的拷贝)虽然在内存中处理都是原子性操作,速度非常快,但是,最后的return语句会创建一个新String对象,限制了concat方法的速度。
String可以直接使用+和+=运算符,这是Java编译器提供的支持,背后,Java编译器一般会生成StringBuilder, +和+=操作会转换为append
既然直接使用 +和+=就相当于使用StringBuilder和append,那还有什么必要直接使用StringBuilder呢?
在简单的情况下,确实没必要。不过,在稍微复杂的情况下,Java编译器可能没有那么智能,它可能会生成过多的StringBuilder,尤其是在有循环的情况下,
public class Demo {
public static void main(String[] args) {
final long start = System.currentTimeMillis();
String str = "hello";
for (int i = 0; i < 1000000; i++) {
str += ", java";
}
final long end = System.currentTimeMillis();
System.out.println(end - start);
final long start1 = System.currentTimeMillis();
final StringBuilder sb = new StringBuilder("hello");
for (int i = 0; i < 1000000; i++) {
sb.append(", java");
}
final long end1 = System.currentTimeMillis();
System.out.println(end1-start1);
}
}
// 看看运行结果,差距极大
需要进行大量字符串拼接时,一定要使用StringBuffer或StringBuilder的append方法:
StringBuffer和StringBuilder的append方法都继承自AbstractStringBuilder,整个逻辑都只做字符数组的加长,拷贝,到最后也不会创建新的String对象,所以速度很快,完成拼接处理后在程序中用strBuffer.toString()来得到最终的字符串
3. 字符串常量池
由于String类型描述的字符串内容是常量不可改变,因此Java虚拟机将首次出现的字符串放入常量池中,若后续代码中出现了相同字符串内容则直接使用池中已有的字符串对象而无需申请内存及创建对象,从而提高了性能。
String直接赋值和使用new的区别
直接赋值: 可能创建一个或者不创建对象
使用new: 可能创建一个或者两个对象,但一定会在heap(堆)中创建一个String对象
public static void main(String[] args) {
String name1 = "tom";
String name2 = "tom";
String str1 = new String("hello");
String str2 = new String("hello");
System.out.println(str1.equals(str2)); // true
System.out.println(str1 == str2); // false (String中"=="比较引用地址,equals比较具体值)
String str3 = "hello";
String str4 = str1.intern();
System.out.println(str3 == str4); // true
}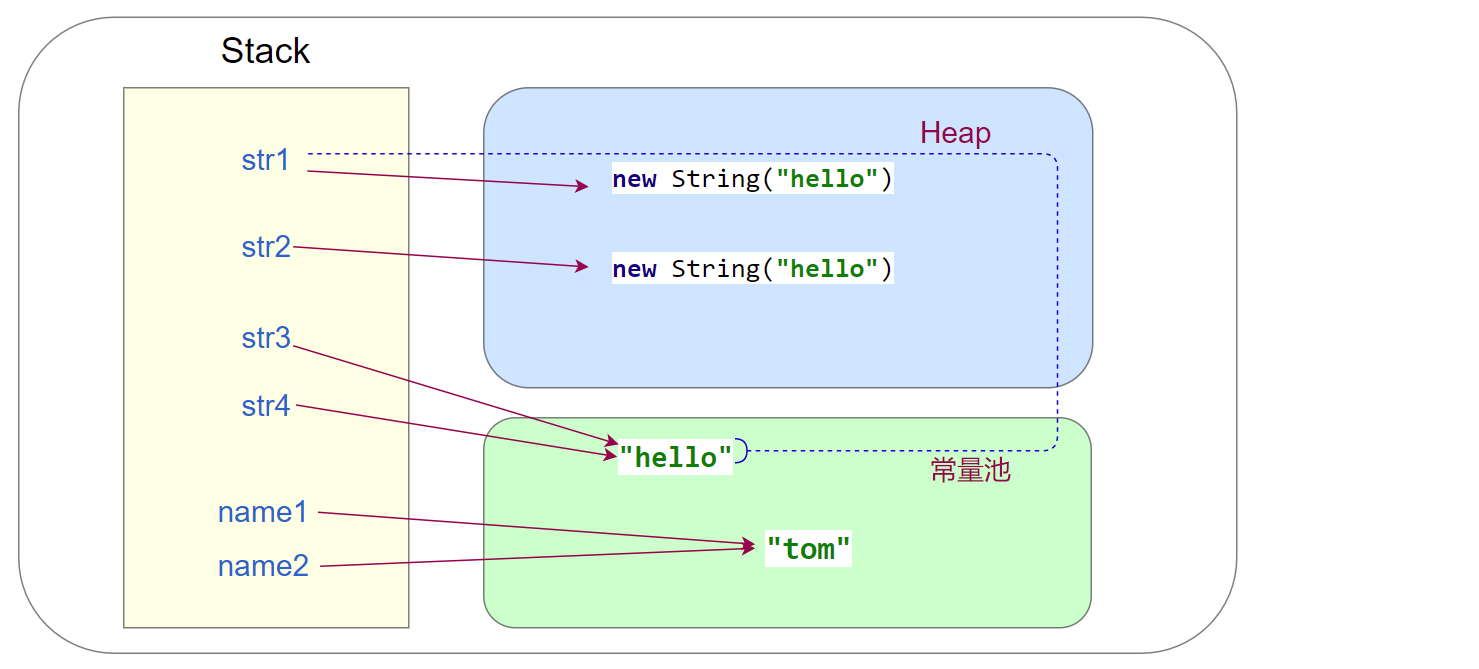
上例中的对象创建解释:
name1:先检查
“tom”在常量池中是否存在,不存在 → 创建“tom”对象放入常量池,并将name1指向该地址name2:由于
“tom”已存在于常量池中,name2直接指向该地址str1:new关键字一定会在heap中创建
"hello",同时会检查常量池中是否存在该对象,不存在 → 则在常量池中创建该对象str2:同样会在heap中创建
"hello",检查到常量池中是已存在该对象后结束str3:由于
"hello"已存在于常量池中,str3直接指向该地址str4:检查常量池已存在这个对象,直接返回其引用
intern():如果常量池中已经包含了这个String对象,那么直接返回这个对象。否则,就向常量中添加这个对象,并返回对它的引用
intern()详解
注意这里从jdk1.7起,复制的是该对象的引用,如下示例:
public class Demo {
public static void main(String[] args) {
String s = new String("aaa");
String s1 = s.intern();
System.out.println(s == s1); // false
String str1 = new String("abc");
String str2 = new String("ddd");
String str3 = str1 + str2;
System.out.println(str3 == str3.intern()); // jdk1.7起为true,之前为false
}
}注:通过new创建一个String对象时,会在创建的同时检查字符串常量池中是否存在该对象,不存在则加入该对象,此处没什么疑问,
关键在于:该例中的字符串进行拼接时,并不会像new一个对象那样进行上述操作(即不会将‘abcddd’加入到常量池),此时 str3 指向一个堆中的对象,而当一个堆中的对象调用 intern() 方法时,从jdk1.7起由于方法区实现的改变,常量池转移到了堆中,成为了堆的一部分,而此处也不再是将该对象再加入常量池然后返回其引用,而是在常量池中加入其在堆中的引用, intern() 返回的也是该引用
==与equals方法有什么区别?
== 与 equals
- == , 对于基本数据类型而言,比较的是内容, 对于引用数据类型而言, 比较的是引用变量, 即所指向的地址
- equals方法 是Object的方法, 默认是比较2个对象的地址, 若要比较内容, 应当重写该方法
4. 可变字符串
String 类是不可变类,即一旦一个 String 对象被创建以后,包含在这个对象中的字符序列是不可改变的,直至这个对象被销毁。
因此Java 提供了两个可变字符串类 StringBuffer 和 StringBuilder,中文翻译为“字符串缓冲区”。
StringBuilder 类是 JDK 1.5 新增的类,它也代表可变字符串对象。
实际上,StringBuilder 和 StringBuffer 功能基本相似,方法也差不多。
不同的是,StringBuffer 是线程安全的,而 StringBuilder 则没有实现线程安全功能,所以性能略高。
因此在通常情况下,如果需要创建一个内容可变的字符串对象,则应该优先考虑使用 StringBuilder 类。
- 操作少量的数据使用 String
- 单线程操作大量数据使用 StringBuilder
- 多线程操作大量数据使用 StringBuffer
// 使用 StringBuilder 拼接字符串, 反转字符串
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("hello");
stringBuilder.append(" world");
System.out.println(stringBuilder.toString()); // hello world
System.out.println(stringBuilder.reverse().toString()); // dlrow olleh5. StringBuilder
与String类得底层final修饰的char数组不同,StringBuilder类继承了 AbstractStringBuilder ,其中有一个 char 类型的数组,但它与String不同,它不是final的,可以修改。
abstract class AbstractStringBuilder implements Appendable, CharSequence {
/**
* The value is used for character storage.
*/
char[] value;
/**
* The count is the number of characters used.
*/
int count;
}
public final class StringBuilder extends AbstractStringBuilder
implements java.io.Serializable, CharSequence {
//
}另外,与String不同,字符数组中不一定所有位置都已经被使用,它有一个实例变量,表示数组中已经使用的字符个数.
StringBuilder继承自AbstractStringBuilder,它的默认构造方法是:
/**
* Constructs a string builder with no characters in it and an
* initial capacity of 16 characters.
*/
public StringBuilder() {
super(16);
}StringBuilder继承自AbstractStringBuilder,它的默认构造方法调用父类的构造方法。也就是说,new StringBuilder()代码内部会创建一个长度为16的字符数组,count的默认值为0。
AbstractStringBuilder类的 append 方法:
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
// minimumCapacity (所需的最小数组长度) 表示加上新插入的字符串后的大小
if (minimumCapacity - value.length > 0) {
value = Arrays.copyOf(value, newCapacity(minimumCapacity));
}
}
private int newCapacity(int minCapacity) {
// overflow-conscious code
int newCapacity = (value.length << 1) + 2;
if (newCapacity - minCapacity < 0) {
newCapacity = minCapacity;
}
return (newCapacity <= 0 || MAX_ARRAY_SIZE - newCapacity < 0)
? hugeCapacity(minCapacity) : newCapacity;
}append会直接复制字符到内部的字符数组中,如果字符数组长度不够,会进行扩展,实际使用的长度用count体现
ensureCapacityInternal(count+len)会确保数组的长度足以容纳新添加的字符,str.getChars会复制新添加的字符到字符数组中,count += len会增加实际使用的长度。
这里的扩展策略是跟当前长度相关的,当前长度左移一位(乘以2),再加上2,如果这个长度不够最小需要的长度,才用minimumCapacity。
比如,默认长度为16,长度不够时,会先扩展到162+2即34,然后扩展到342+2即70,然后是70*2+2即142,这是一种指数扩展策略。为什么要加2?这样,在原长度为0时也可以一样工作。
为什么要这么扩展呢?
这是一种折中策略,一方面要减少内存分配的次数,另一方面要避免空间浪费。
== 在不知道最终需要多长的情况下,指数扩展是一种常见的策略,广泛应用于各种内存分配相关的计算机程序中==。
不过,如果预先就知道需要多长,那么可以调用StringBuilder的另外一个构造方法:
public StringBuilder(int capacity) {
super(capacity);
}字符串构建完后,通常需要调用toString方法的代码,返回一个String类型的字符串:
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}这里新建了一个String。注意,这个String构造方法不会直接用这个可变的value数组,而会创建String对象,以保证String的不可变性。
6. StringBuffer
四 正则表达式
正则表达式(Regular Expression)又称正规表示法、常规表示法,在代码中常简写为 regex、regexp 或 RE
正则表达式定义了字符串的模式、可以用来搜索、编辑或处理文本。
1. Java regex
java.util.regex 包下主要包括以下三个与正则表达式相关的类:
Pattern 类:
pattern 对象是一个正则表达式的编译表示。
Pattern 类没有公共构造方法。要创建一个 Pattern 对象,必须首先调用其公共静态编译方法,它返回一个 Pattern 对象。
Matcher 类:
Matcher 对象是对输入字符串进行解释和匹配操作的引擎。
与Pattern 类一样,Matcher 也没有公共构造方法。需要调用 Pattern 对象的 matcher 方法来获得一个 Matcher 对象。
PatternSyntaxException:
PatternSyntaxException 是一个非强制异常类,它表示一个正则表达式模式中的语法错误。
// java中正则表达式的简单使用示例
@Test
public void testMatches(){
String content = "lksdfldsfldsjavafhlsdkjfdlsf";
String pattern = ".*java.*";
boolean isMatch = Pattern.matches(pattern, content);
System.out.println(isMatch); // true
}2. 表达式语法
在其他语言中,\\ 表示:在正则表达式中插入一个普通的(字面上的)反斜杠,没有任何特殊的意义
在 Java 中,\\ 表示:插入一个正则表达式的反斜线,所以其后的字符具有特殊的意义。
所以,在其他的语言中(如 Perl),一个反斜杠 \ 就足以具有转义的作用,而在 Java 中正则表达式中则需要有两个反斜杠才能被解析为其他语言中的转义作用。也可以简单的理解在 Java 的正则表达式中,两个 \\* 代表其他语言中的一个 \
如:Java中表示一位数字的正则表达式是 \\d, 而表示一个普通的反斜杠是 \\。
Java中与正则表达式相关的几个特殊的方法:
boolean matches(String regex):判断该字符串是否匹配指定的正则表达式。String replaceAll(String regex, String replacement):将该字符串中所有匹配 regex 的子串替换成 replacement。String replaceFirst(String regex, String replacement):将该字符串中第一个匹配 regex 的子串替换成 replacement。String[] split(String regex):以 regex 作为分隔符,把该字符串分割成多个子串。